NVIDIA TAO Toolkitを活用したエッジAI推論環境の構築(Part 2)

本ブログでは前回に続き、NVIDIA TAO Toolkit を活用して作成したAIモデルを使って、当社で取り扱っているエッジデバイスで実際に推論を実行するまでのプロセスを紹介していきます。今回は、前回紹介したNXP社製のFRDM i.MX93開発ボードを使って、実際にカメラ画像に写る人物を検出するAI推論を動かしていこうと思います。前回ブログをご覧になっていない方は、ぜひ前回ブログからご覧ください。
TAO Toolkitモデルダウンロード
まず初めに、動作させたいAIモデルの準備を行います。
以前から紹介しているNVIDIA TAO Toolkitでは、単にAIモデルの作成を簡素化するだけでなく、学習時間短縮のために多くの事前学習済みモデル(チェックポイント)が提供されています。
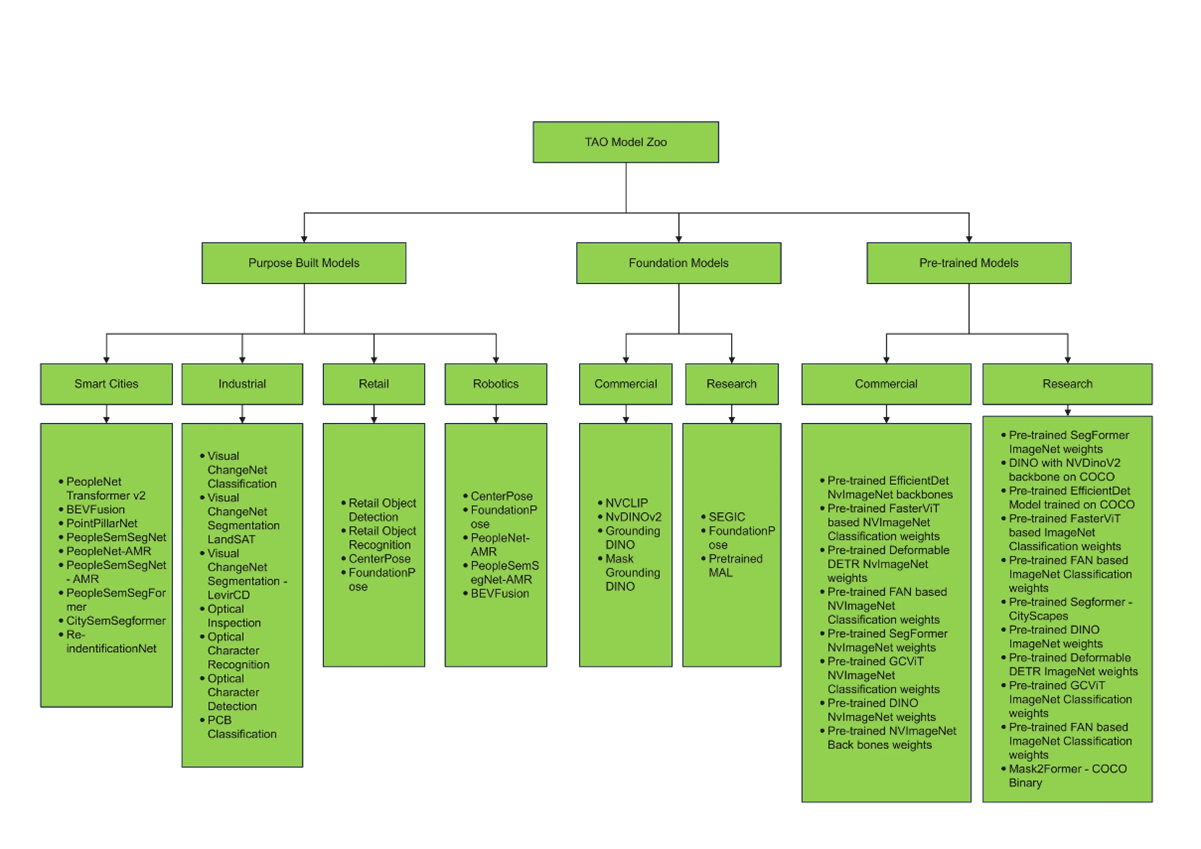
図のように多くの事前学習済みモデルが提供されており、ユーザーは用途に適したモデルを自身のデータでカスタマイズすることで、即座に推論アプリケーションを実行することができます。
今回のブログでは、この事前学習済みモデルの中からPeopleNetモデルを使って、人物検出のAI推論を行っていこうと思います。このPeopleNetモデルは、ResNet34を元に作られたDetectNetV2モデルで、人、バッグ、顔の三つのカテゴリのオブジェクトを検出できるように学習したものです。

※参照:NVIDIA社提供
モデルは以下のNVIDIA NGC CatalogからONNX形式のものをダウンロードできます。
※NVIDIA NGC Catalog:PeopleNet
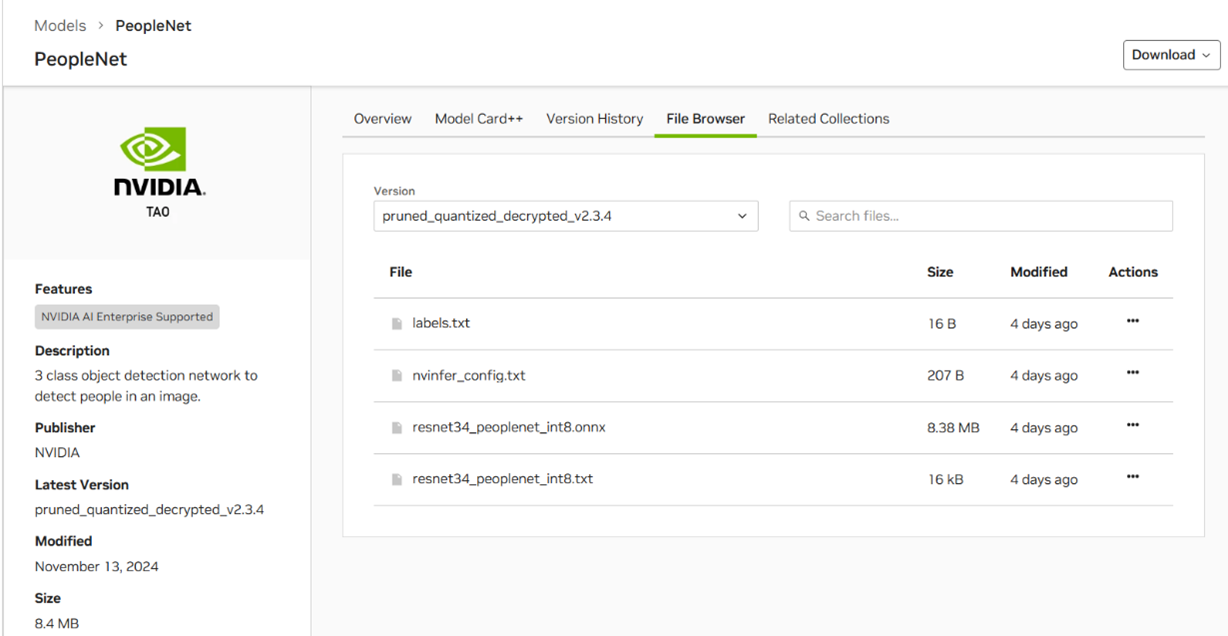
※参照:NVIDIA
また、本モデルを独自のデータでカスタマイズしたい場合には、以下NVIDIA NGC Catalog内のTAO Toolkit Quick Startにて配布されているノートブックを参考にしてください。
※NVIDIA NGC Catalog:TAO Toolkit Quick Start
モデルの変換
TAO ToolkitよりエクスポートされたモデルはONNX形式になっていますが、このままFRDM i.MX93開発ボード上にデプロイできるわけではありません。モデルをFRDM i.MX93開発ボードで効率的に実行するには、量子化されたTensorFlow Lite形式に変換する必要があります。変換手順を以下にまとめます。
- ONNXモデルの入出力テンソル名には「:O」というサフィックスついているため、これを削除します。
- ONNXモデルがNCHW形式なのに対し、TensorFlowモデルはNHWC形式である必要があるため、モデル形式を変換します。この変換にはOpenVINOとopenvino2tensorflowを使用します。
- TensorFlowモデルを量子化されたTensorFlow Liteモデルに変換します。
※Arm Cortex-A55 CPUで動作させる場合には、このモデルを使用します。 - Arm Ethos-U65 NPUで実行するために、Velaコンパイラを使ってコンパイルします。
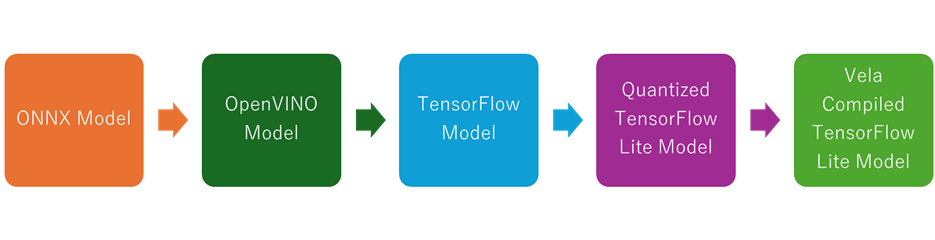
上記変換手順に必要なコードは以下のGithub内のNotebookにまとまっています。NVIDIA NGC CatalogよりダウンロードしたONNX形式のモデルをNotebookと同じディレクトリに配置し、Notebook内のコードを実行するだけでArm Ethos-U65 NPU上で実行するために必要なTensorFlow Liteモデルに変換できますので、参考にしてください。
※Github:モデル変換Notebook
推論環境準備
AIモデルの準備が終わりましたので、次は推論環境の準備を行っていきます。
今回はFRDM i.MX93開発ボード上にて人物検出のAI推論を動作させますが、そのために必要なハードウェアのリストを以下に記載します。
- FRDM i.MX93開発ボード
- ディスプレイ(HDMI接続)
- USB webカメラ
- キーボード
- マウス
- USBハブ(Type A) ※カメラ、キーボード、マウス接続のため
- USBケーブル(Type C) ※電源用ケーブル
- USB電源(Type C)
- 32GB microSD ※プリインストールOS以外のOSを使用したい場合のみ
これらをすべて接続すると以下の写真のようになります。

ディスプレイを除けば、2~3万円程度ですべてそろえることができるので、ぜひ参考にしてください。
さて、ハードウェアのセットアップは終わったので、さっそく推論環境をデプロイしていこうと思います。といっても、今回使用するFRDM i.MX93開発ボードにはeMMC上にYocto Linuxがプリインストールされており、推論実行に必要なPython環境などもインストール済となっています。そのため、動かしたいAIモデルと推論アプリケーションのみ準備すれば、即座に推論を実行可能です。
AIモデルはTAO ToolkitのONNXモデルをTensorFlow Liteモデルに変換したものを準備したので、あとは推論アプリケーションを準備します。今回のブログでは以下のGithubにあるものを使用します。
Github:物体検出推論アプリ
このPythonアプリケーションの概要は以下です。
- ビデオキャプチャデバイスから画像をキャプチャする
- キャプチャした画像を960×544にパディングする
- サイズ変更した画像をBGR形式からRGB形式に変換する
- RGB 画像で AI推論を実行し、各セルのスコアと境界ボックスを出力
- 出力を後処理し、スケールとオフセットを適用
- NMSクラスタリングを適用
- 最小高さしきい値未満のボックスを除外
- 境界ボックス付きの画像を表示
この推論アプリケーションと先に変換したTensorFlow LiteモデルをFRDM i.MX93開発ボード上に配置すれば準備完了です。
推論の実行
それでは早速実行していきましょう。
Githubから推論アプリケーションをクローンし、TensorFlow Liteモデルはクローンしたディレクトリ内に配置してください。その後、ディレクトリ内で以下のコマンドを実行すれば推論アプリケーションが実行されます。
python3 main.py resnet34_peoplenet_int8_vela.tflite
実行した結果の写真が以下です。
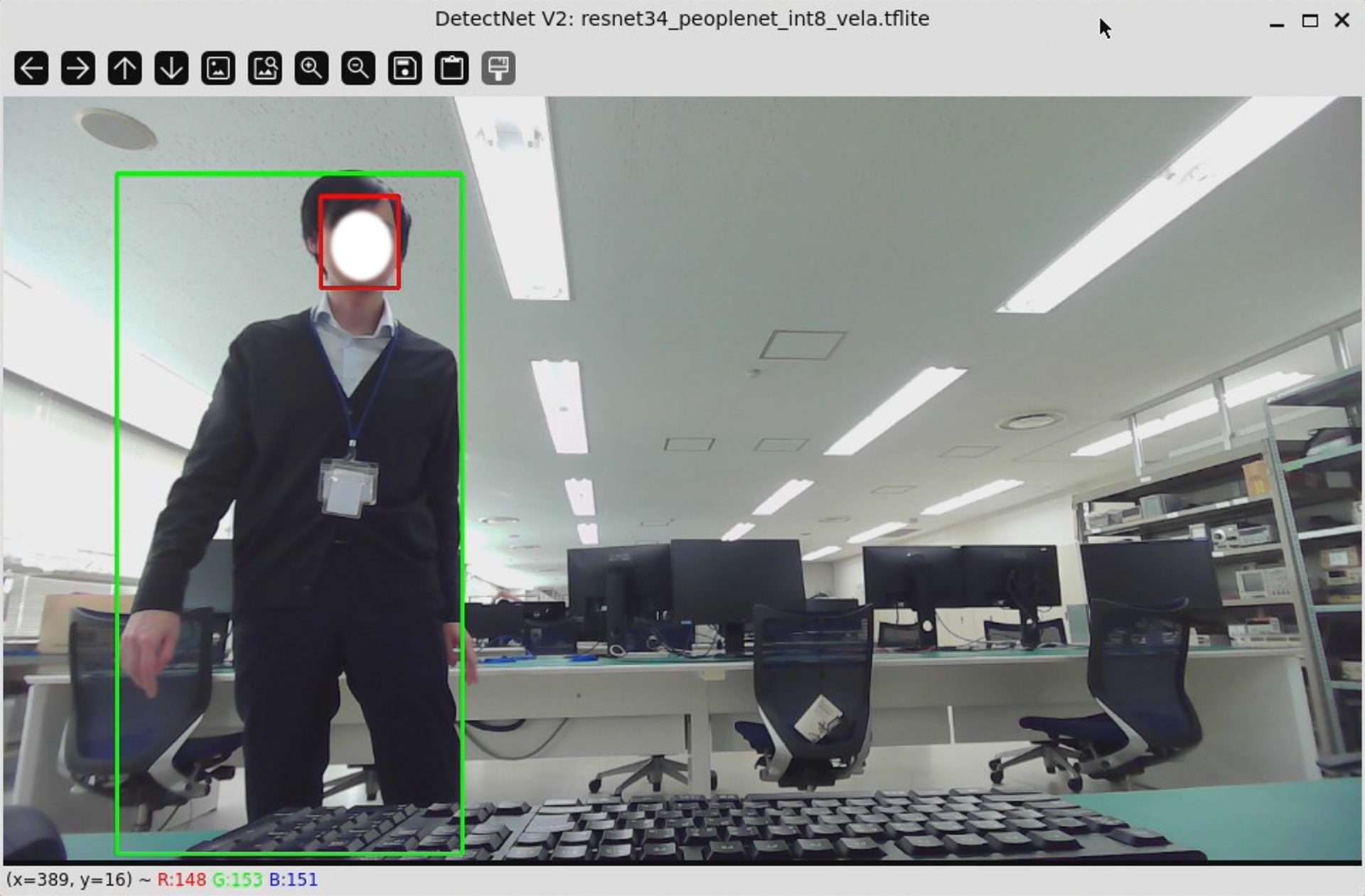
しっかりとカメラに写った人物とその顔を検出できていると思います。また、画像ではわかりませんが、カメラ内の人物が動いてもボックスは滑らかに人物に追随しました。これはi.MX93に搭載されているArm Ethos-U65 NPUによってAI推論が高速に処理されているためです。
先と同じコマンドを使ってArm Cortex-A55 CPU上でも推論を実行することができますが、CPU上で実行した場合、推論速度が遅いためボックスはカメラ内で動く人物をうまく追随することができませんでした。CPU上で推論を実行するコマンドは以下です。
python3 main.py resnet34_peoplenet_int8.tflite
※resnet34_peoplenet_int8.tfliteはVelaでコンパイルしていないモデルです。
実際に、Arm Ethos-U65 NPUとArm Cortex-A55 CPUそれぞれで推論を実行した場合のベンチマーク結果を以下に表示します。
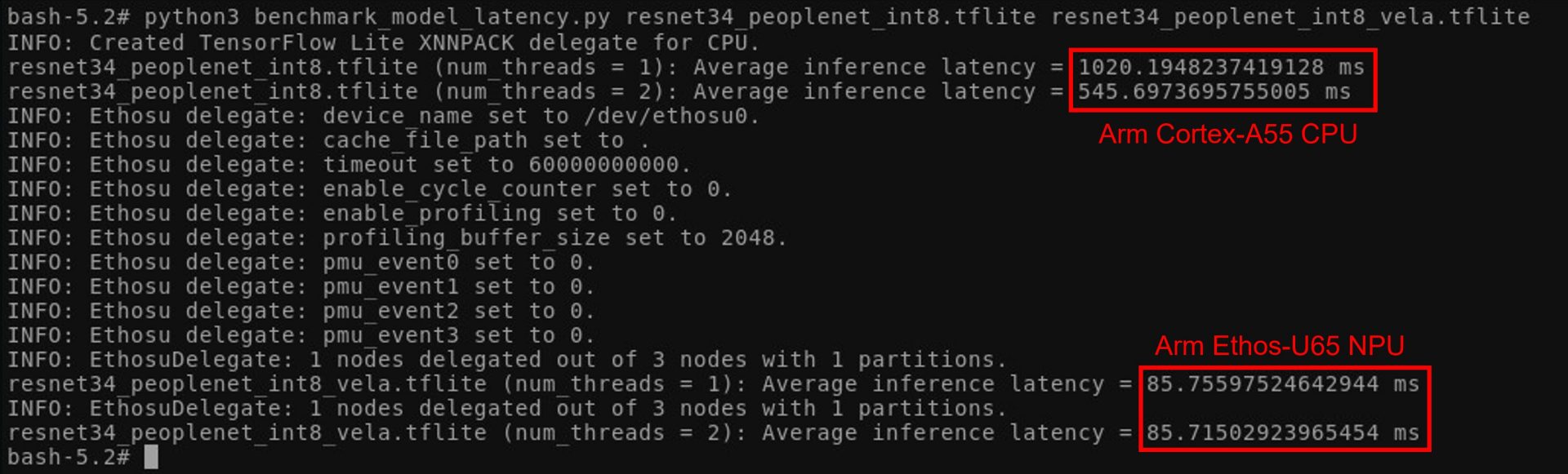
CPUとNPUでは推論レイテンシに一桁以上の差ができています。このことからも、推論環境を検討する際には、エッジデバイスの選定が非常に重要であることがわかっていただけたと思います。
最後に
今回のブログでは、NVIDIA TAO ToolkitとNXP社製 FRDM i.MX93 開発ボードを使用して、実際にAI推論環境を構築する方法をご紹介しました。Part1、2を通して、エッジデバイス選定の重要性だけでなく、NVIDIA TAO ToolkitとNXP社製 FRDM i.MX93 開発ボードを使った推論環境構築のお手軽さも感じていただけたなら幸いです。
もし「NVIDIAソフトウェアスタックを使ってみたいが環境が無い」、「設定方法や使い方がわからない」などの理由でお困りの場合には、ぜひ当社にご相談ください。当社では、TED AI Lab環境をお客様へお貸出しするTED AI Lab Engineering Service(TAILES)というサービスを提供させていただいております。TAILESでは、単に機器をお貸出しするだけでなく、当社エンジニアが環境設定から使用方法まで手厚くサポートさせていただいておりますので、本稿にて紹介したようなAIパイプラインを即座に体験することができます。
ブログをお読みになり、NVIDIA製品、TED AI Lab、TAILESにご興味がある方はぜひ当社までお問合せ下さい。

この記事の投稿者goto
この記事をシェア



