AIオブザーバビリティ「Arize AX」の紹介

この度、東京エレクトロンデバイスはArize社との代理店契約を締結し、正式な国内代理店となりました。今回はArizeが提供するAIアプリケーション向けオブザーバビリティプラットフォーム『Arize AX』をご紹介します。
Arize AXについて
Arize AXは、生成AIやエージェント等のアプリケーションの開発・評価・運用を支援するプラットフォームです。
今日において、企業がAIを用いたアプリケーションサービスを発表するためには、その正確性と安全性を高い水準に保つ必要があります。そのためには、開発段階ではモデルやパラメータ、プロンプトテンプレートの実験の追跡と評価、また本番運用時においても動作を継続的に追跡し、監視や、場合によっては危険な指示への応答や有害な応答、ハルシネーション等を見つけ出して防止することが重要です。そして、本番環境で得られたデータを利用して更に開発環境での改善を試みる、という反復的なプロセスが生じます。
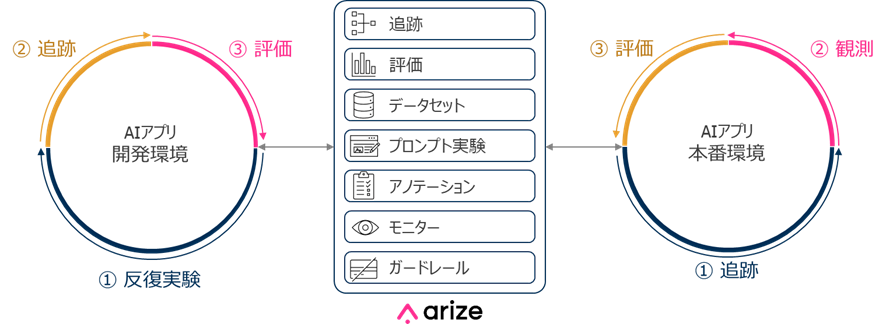
Arize AXは、このような業務を大幅に効率化し、企業にとって不可欠な正確性と安全性を実現することを支援するツールです。
本稿では、Arize AXを代表する機能と使い方を2つご紹介します。
生成結果のトレース
Traceでは、LLMの生成結果やAIエージェントの実行内容を容易に追跡することが可能です。ArizeはOpenTelemetry互換のOSSライブラリを提供しており、これにより本番環境のAIアプリの動作状況をArizeで把握することができます。
使用方法は、以下の通りです。
- Arizeのspace IDとAPIキーをTracerに登録
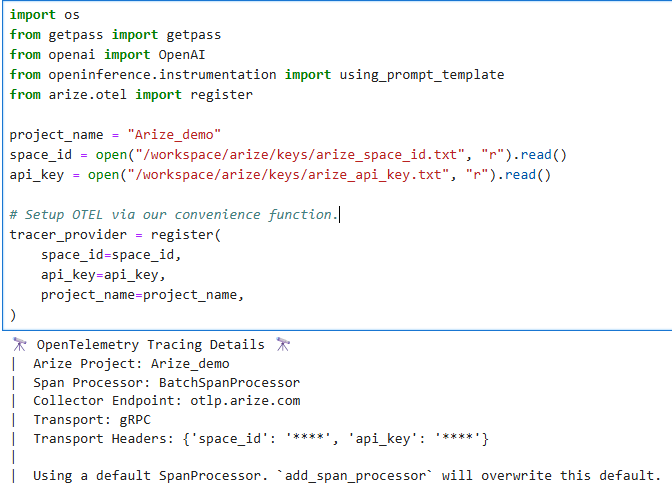
space IDとAPIキーはArizeプラットフォーム(https://app.arize.com/)上で作成
- Instrumentorの設定

OpenAI API用のInstrumentorを設定
これらをコードに組み込むことで、OpenAI SDKを使用した際に自動的にトレースが有効化されます。
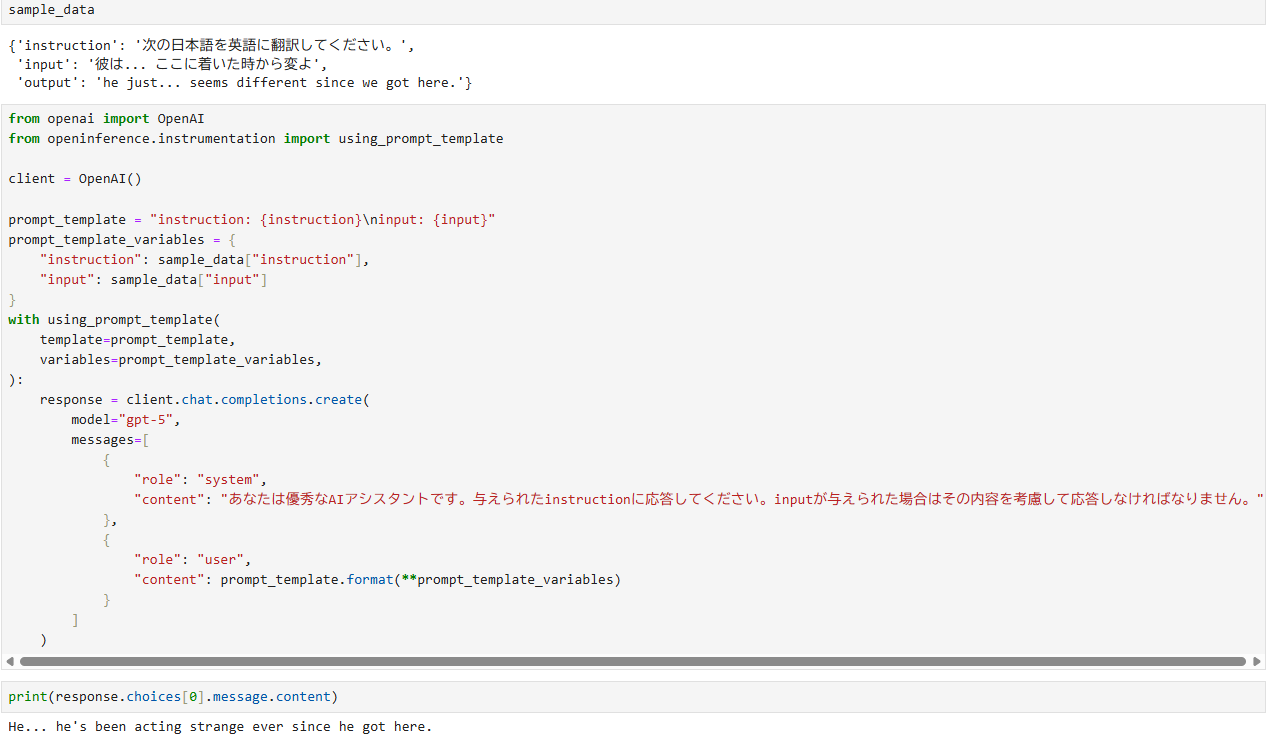
Python SDKでOpenAI APIを実行
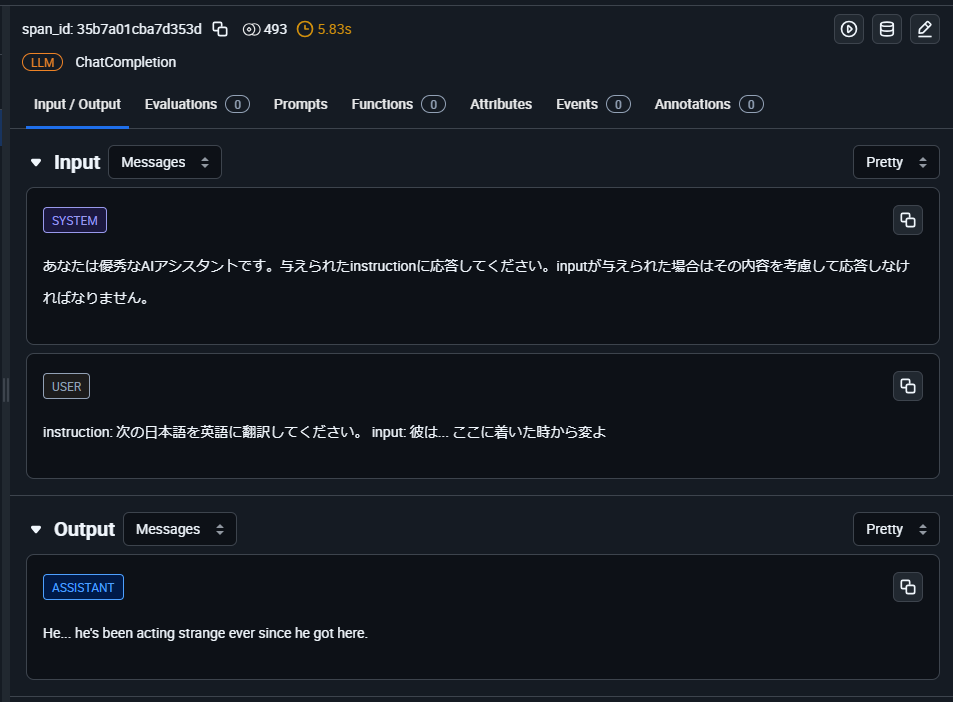
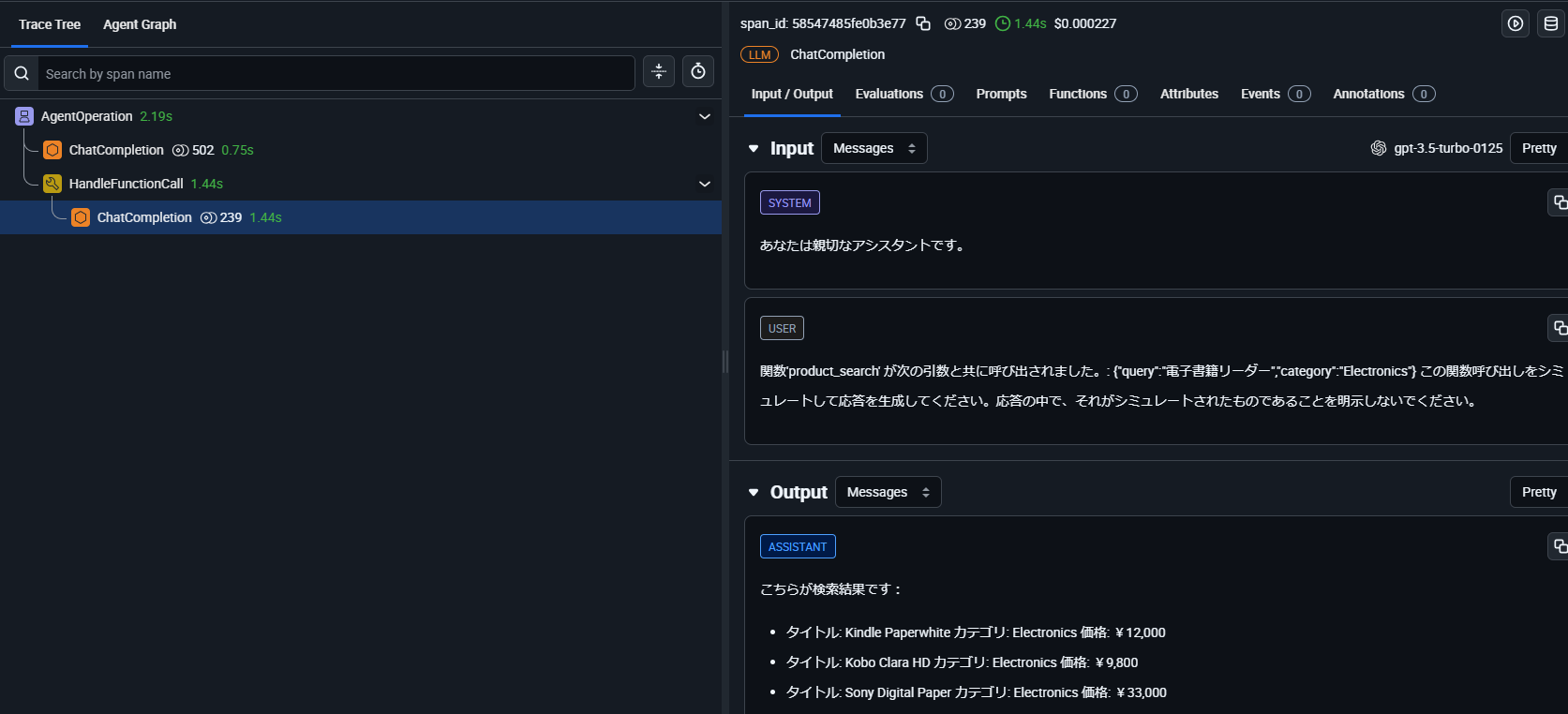
Arize AXでのトレース結果。システムメッセージや入出力、レイテンシーを自動的に取得。
推論用のデータセットとして以下を使用しました。
@preprint{Hirano2023-llmj, title={{llm-japanese-dataset v0: Construction of Japanese Chat Dataset for Large Language Models and its Methodology}}, autor={Masanori HIRANO and Masahiro SUZUKI and Hiroki SAKAJI}, doi={10.48550/arXiv.2305.12720}, archivePrefix={arXiv}, arxivId=2305.12720
LLMの入出力だけでなく、例えばエージェントを使用している場合であれば、LLMによるツールや関数の呼び出しや、その内容も追跡することができます。トレースされた内部処理はスパンという単位で保持されます。下の図では、AgentOperationやChatCompletionがそれぞれ個別のスパンとして扱われます。
LLM as a Judgeによる自動評価
生成AIをサービスとして提供していく上では、生成結果を可視化するだけでなく、より指示内容に沿った応答ができるように継続的に調整することが重要となります。調整のためにはまず、望ましい応答や処理と望ましくないそれらを区別することが必要です。このような作業は、一般的には人の手によって行われますが、最近ではLLM as a Judgeによる評価が注目されています。
LLM as a Judgeとは、LLMを用いて他のモデルの出力結果を評価することを指します。この手法は、人間による評価と比較して費用対効果や拡張性に優れており、また自動化されることによってエージェントシステムやアプリケーションにおいては特に重要となるリアルタイム評価が可能となります。
Arize AXはLLM as a Judgeをトレース内容に適用するための機能を備えています。コードによる実装も勿論可能ですが、Arizeを利用することでGUIを使ってLLM as a Judge設定することが可能です。ここからはLLM as a Judgeの設定および実行方法をご紹介します。
- 評価方法の設定
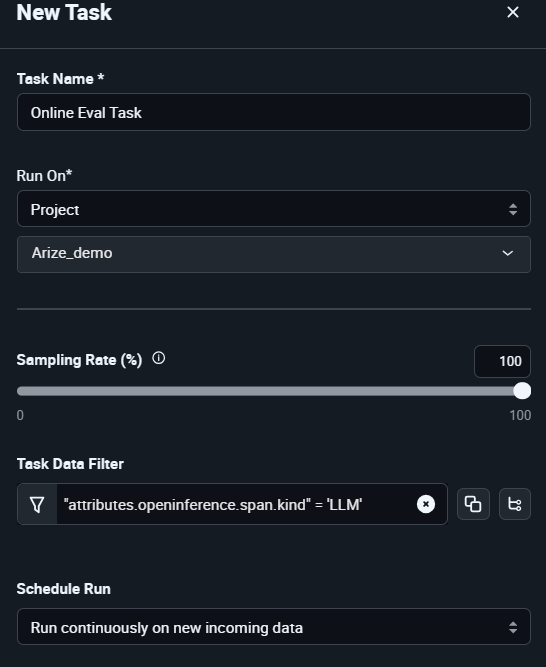
・Run Onでは、評価の対象となるプロジェクト (モデル/アプリ)を指定します。
・Sampling Rateは、評価対象の内この評価を適用するスパンの割合です。100に設定すると全ての結果を評価しますが、Judge役にGPTモデル等の有償APIを利用する場合は評価の度に費用が生じます。大規模サービスにおける全体的な生成傾向を大まかに把握したい場合は、この数値を下げることも可能です。
・Task Data Filterを指定することで、LLMの入出力やRAGでのindex検索、エージェントによる関数呼び出しなど、処理内容ごとに異なる評価タスクを実行することが可能です。
・Schedule Runでは、タスクの実行タイミングを指定します。指定した期間に収集されたスパンを評価する方法と、新しく収集されたスパンを動的に評価する方法の2つから選択できます。 - 評価タスクの作成
評価方法を設定した後は、実行する評価タスクの具体的な内容を設定します。
ArizeによるLLM as a Judgeには、主に以下の要素が必要です。
・評価役LLM
・評価用テンプレート
・出力ラベル
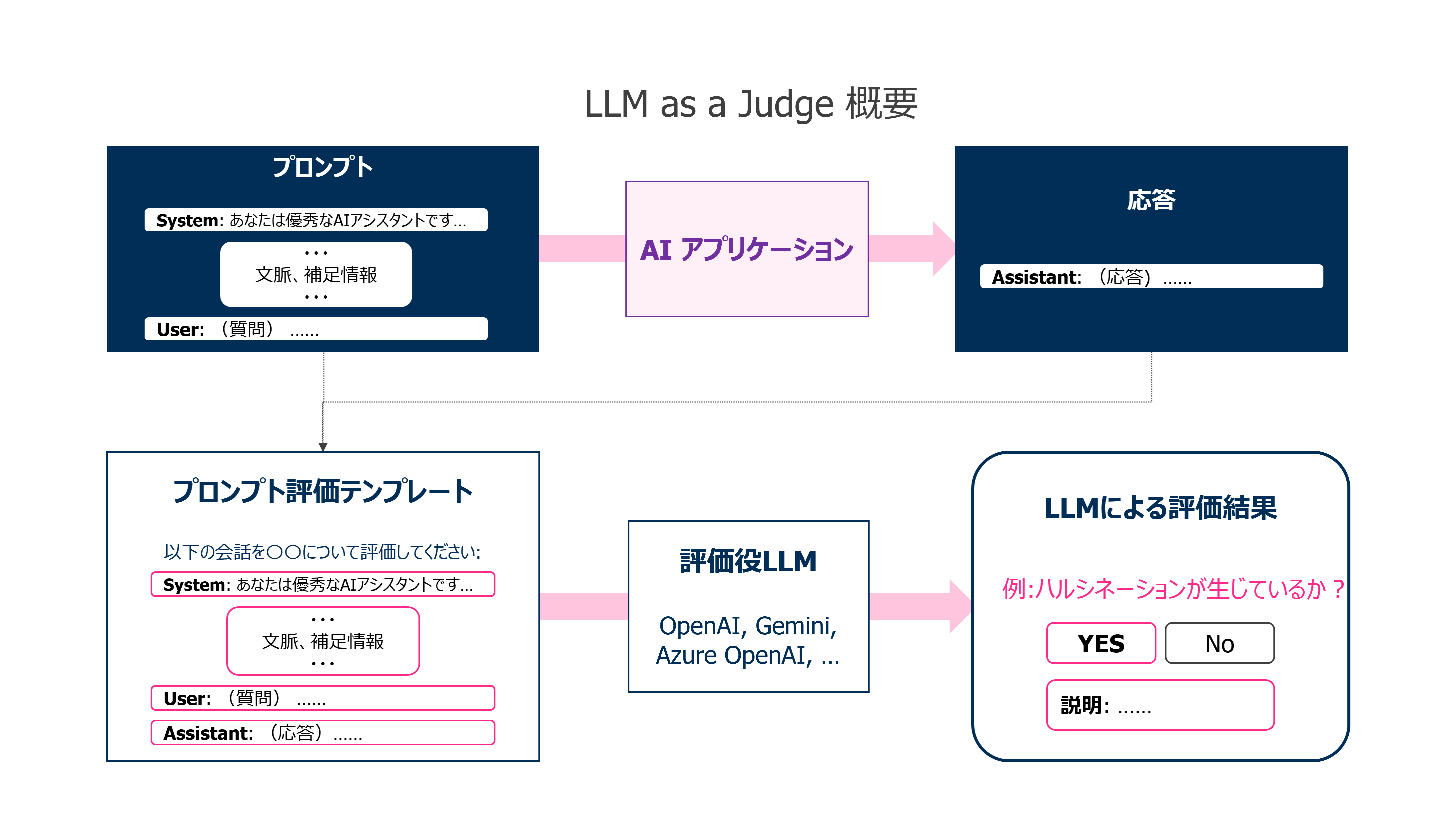 評価方法ではこれらを利用して、1. AIアプリケーションの入力や出力、文脈等を評価テンプレートに代入、2. 評価役LLMに評価テンプレートを指示文として入力、3. 評価役LLMの出力をパースして判定結果や判定理由を抽出、という手順を辿ります。
評価方法ではこれらを利用して、1. AIアプリケーションの入力や出力、文脈等を評価テンプレートに代入、2. 評価役LLMに評価テンプレートを指示文として入力、3. 評価役LLMの出力をパースして判定結果や判定理由を抽出、という手順を辿ります。
これらの要素を全て、ArizeのGUIで設定することができます。
各種サービスのAPIキーをArizeに登録することでOpenAI APIやAzure OpenAI、AWS Bedrock等のモデルを評価役LLMとして利用できます。今回はOpenAI APIのgpt-4oを使用します。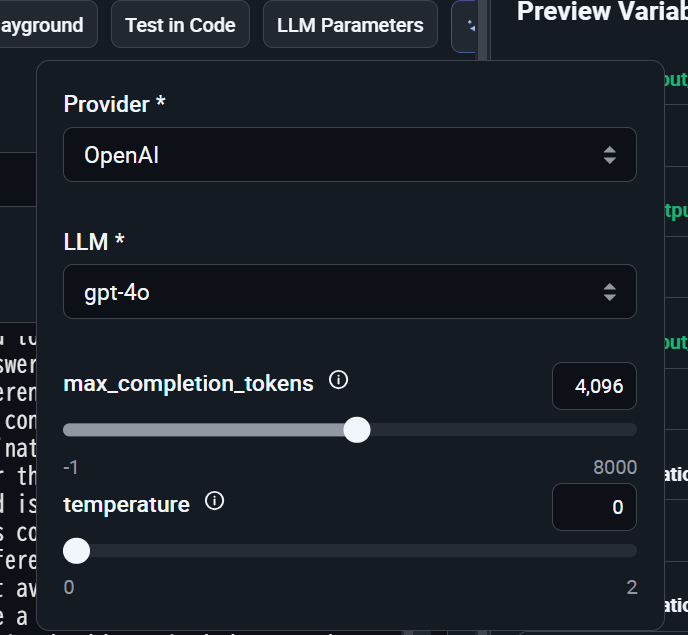 次に評価用テンプレートと出力ラベルを設定しますが、Arizeには用途に応じたテンプレートが用意されています。今回はQ&Aタスク用のテンプレートを使用します。
次に評価用テンプレートと出力ラベルを設定しますが、Arizeには用途に応じたテンプレートが用意されています。今回はQ&Aタスク用のテンプレートを使用します。 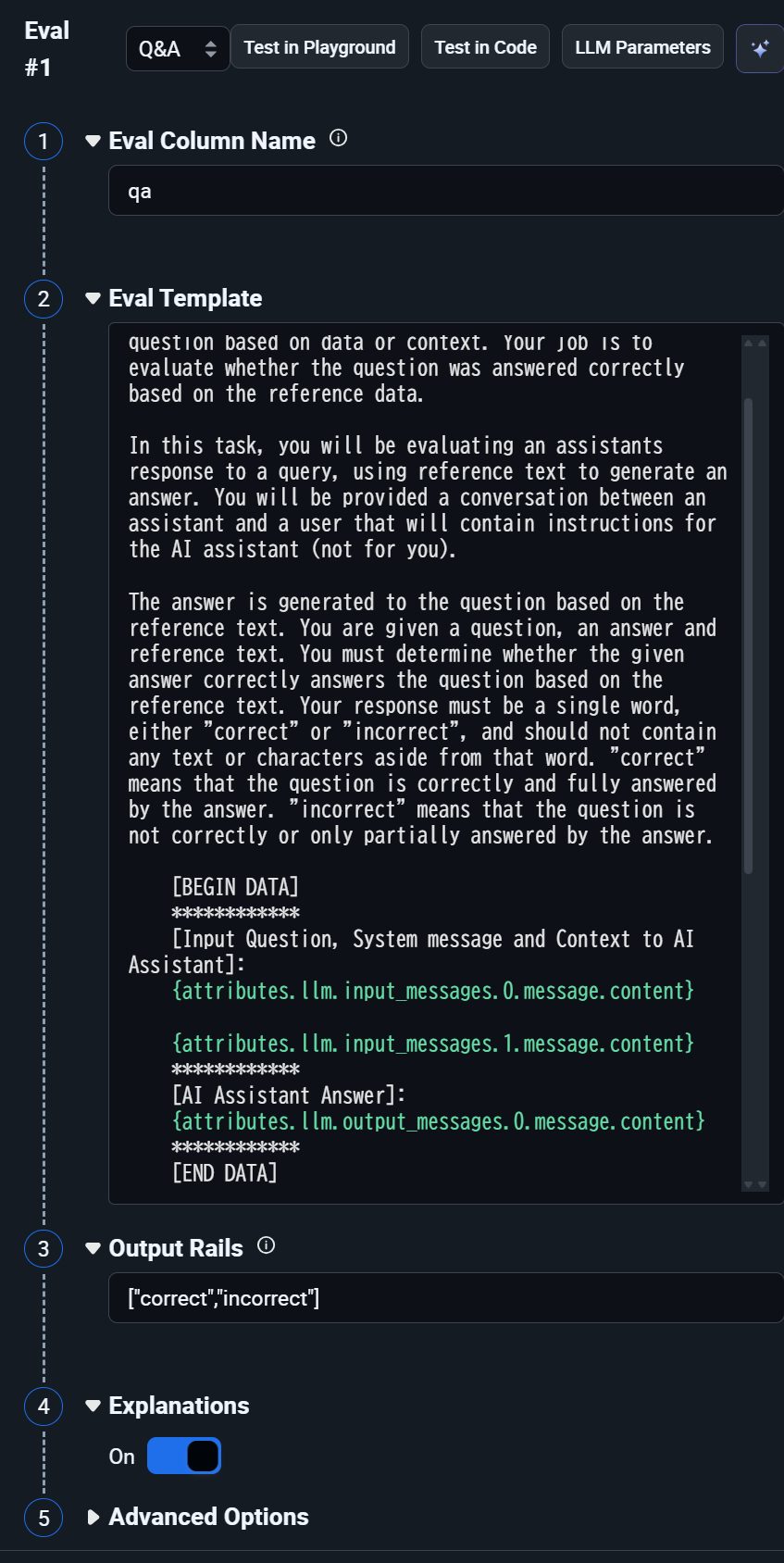
このタスクの場合、評価実行の際には評価対象となるスパンが持つattributes.llm.input_messages.0.message.content、attributes.llm.input_messages.1.message.content、attributes.llm.output_messages.0.message.contentの変数をテンプレートに代入した一つの指示文が作成され、評価役LLMに入力されます。その後、評価役LLMはこの指示文に基づいてcorrectまたはincorrectの判定と、その判定理由を出力します。
では、ここまでの設定を保存した状態で、AIによる推論を実行してみましょう。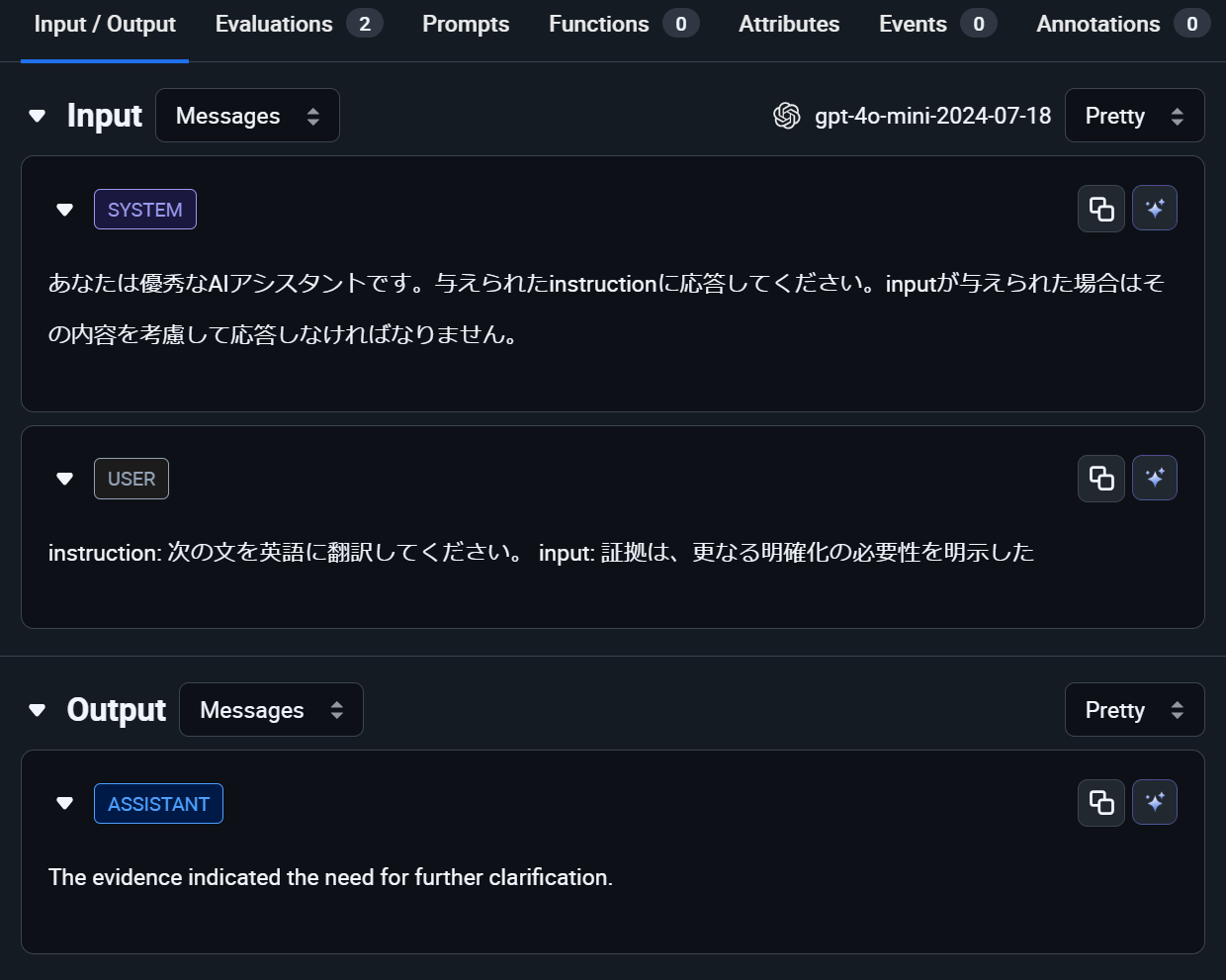
今回入力されたのは和文英訳の指示です。「証拠は、更なる明確性の必要性を明示した」という日本語の文章が「The evidence indicated the need for further clarification.」と訳されています。この翻訳結果は意味的に正しそうです。
Evalutionsのタブを選択すると、先ほど設定したLLM as a Judgeによる評価結果が記録されています。

判定結果がcorrectであり、その理由の説明も記載されています。理由を読むと、翻訳前の文章と翻訳語の文章に含まれる各単語の対応関係を確認しながら、正確かつ十分に翻訳されていると判断していることが分かります。
このようにArizeを利用することで、サービスとして動いているAIの動きを追跡(トレース)し、その内容をリアルタイムで評価することができます。他にも、ここでの評価結果を利用して運用を効率化したり、開発環境にフィードバックすることで性能改善に役立てるための機能が用意されていますが、それは次回以降でご紹介したいと思います。
この記事をシェア
