【巨大ディープラーニングモデルにミッションクリティカルサーバーという選択肢】AIモデル学習にSuperdome Flex× Cerebras

本ブログでは、AIおよびHPC用途に最適なHPE Superdome Flex Familyと、巨大なチップを備えたディープラーニング専用システムであるCerebras CS-2を組合せたソリュ―ションについてご紹介します。
みなさん、こんにちは
Cerebrasプリセールスエンジニアのnakadaです。
今回は、AIおよびHPC用途に最適なHPE Superdome Flex Family(以下、Superdome Flex)と、巨大なチップを備えたディープラーニング専用システムであるCerebras CS-2(以下、Cerebras)を組合せたソリュ―ションについてご紹介します。また、おすすめしたいオンラインセミナーについても 最後にご紹介しておりますのでご興味のある方はご参加ください!
本稿は、Superdome Flexを販売している日本ヒューレット・パッカード合同会社様との連載ブログとなっています。日本ヒューレット・パッカード合同会社様のブログも併せてご覧ください。
■最強のサーバープラットフォームSuperdome Flex
みなさんは、様々なIT環境を構築する際に必ず利用するハードウェアの一つというと何でしょうか。ネットワークスイッチ、ストレージそしてサーバーではないでしょうか。今回は、Superdome Flexがなぜ最強のサーバープラットフォームなのかをご紹介し、なぜディープラーニング専用システムであるCerebrasとの組み合わせが実現したのかについてお話します。
Superdome Flexの最大の特徴は単一システムを段階的に拡張できる点です。通常のサーバーでもメモリやハードディスクの拡張は可能ですが、拡張できる規模が桁違いです。初期導入では5Uの1筐体(4ソケット/768GBメモリ)からスタートでき、最大拡張では 8 筐体を連結することで32 ソケット 896 コア/48 TBメモリまでスケールさせることが可能です。この拡張性により、単一システムにもかかわらず増大するデータを高速に解析することが可能になります。
更に、幅広いワークロードをサポートするためにPersistent Memory (不揮発性メモリ)や多種多様な I/O カードをなんと最大128枚までサポートしています。私たちが使っている汎用的なサーバーのレベルとは次元が違います。
また、Superdome Flexファミリーには、もう一つ「 HPE Superdome Flex 280 」があります。このサーバーでは1筐体に 2 ソケット / 64 GBメモリからスタートすることが可能で、最大構成では8ソケット/24TBメモリまでスケールできるため、よりきめ細かいハードウェア構成を選択することも可能です。

■Superdome Flex+Cerebras
CerebrasとSuperdome Flexの新しいソリューションを具体的にご紹介します。
昨今、翻訳や文章生成、文章分類の分野ではBERTやGPTという自然言語処理のディープラーニングモデルが有名ですが、自然言語モデルに共通することは、とても大きなニューラルネットワークを構成する点です。これにより学習されるマシンのメモリ量や計算速度が重要になってきます。このような大きなニューラルネットワークを処理するのに最適な解はCerebrasのようなディープラーニング専用のシステムを利用することです。Cerebrasは世界最大の巨大チップであるWaferScaleEngineを備えたシステムです。

※Cerebrasのより詳細な説明は当社サイトご確認ください。
このシステムは、一言で表すとネットワークアタッチドアクセラレータ(ネットワーク上にあるアクセラレータ)となっています。普段みなさんがディープラーニングで利用するサーバーと言えば、GPUチップが搭載されたGPUサーバーだと思いますが、CerebrasはサーバーとGPUチップとを分離して、GPUチップ部分のみのシステムとして利用します。これにより、チップ自身の大きさや消費電力に制限を受けることなく、巨大で高速処理が可能なアクセラレータシステムとして利用することができます。
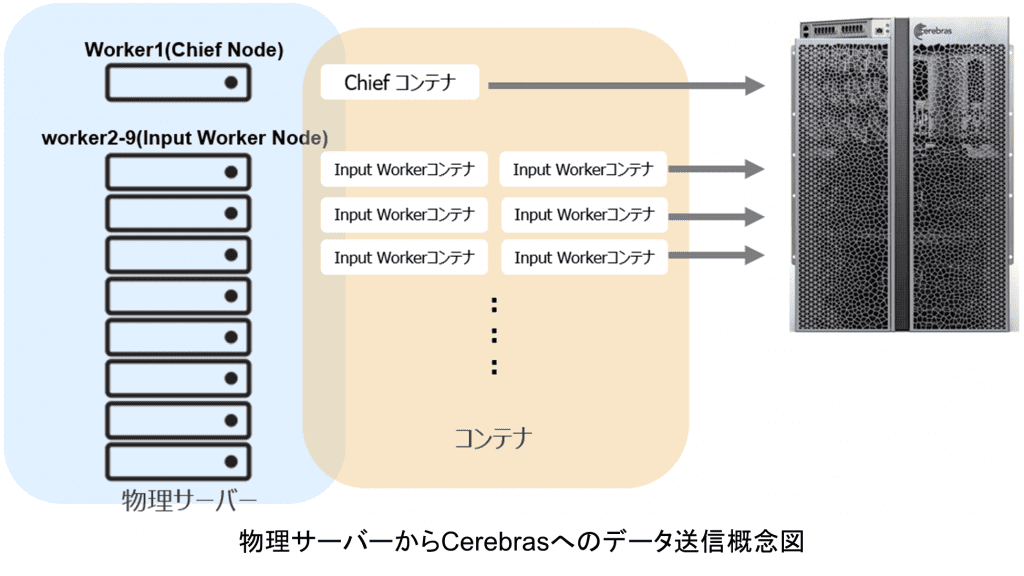
サーバーとGPUチップを分離するので、サーバーにはそれほどスペックは要らないのではと思う方もいると思いますが、それはNoです。なぜなら、Cerebrasの処理性能が高いゆえに、Cerebrasに送るデータ(データセットやパラメータ等)を大量に効率良く送受信する必要があります。そのため、Cerebrasを利用するためには、複数のサーバーを用意し、同時にデータを送受信する必要があります。
この複数のサーバーを単一システムにまとめることができたら、どうなるでしょうか?ソフトウェア・ハードウェアの設定が1台で済みますし、運用を考えた場合、監視数の削減も可能となります。そして、複数のサーバーよりも高性能なサーバーがあるとしたら…
その答えが、複数のサーバーと比べても圧倒的な性能を誇るSuperdome Flexです。Cerebrasと組合せることで、巨大化するディープラーニングで問題とされている学習時間の改善と増大するサーバーやGPUの数を削減することができ、その結果、AIモデル開発のスピードアップや効率化が達成できると信じています。
■当社のTED AI LabにてPoCを開始しました!
日本ヒューレット・パッカード合同会社様のブログで紹介されていますように、当社のTED AI Labにて、Superdome Flex 280とCerebrasを使ったPoCを開始しました。

Superdome Flex 280とCerebras
Superdome FlexとCerebrasとの接続構成は以下の図となっています。
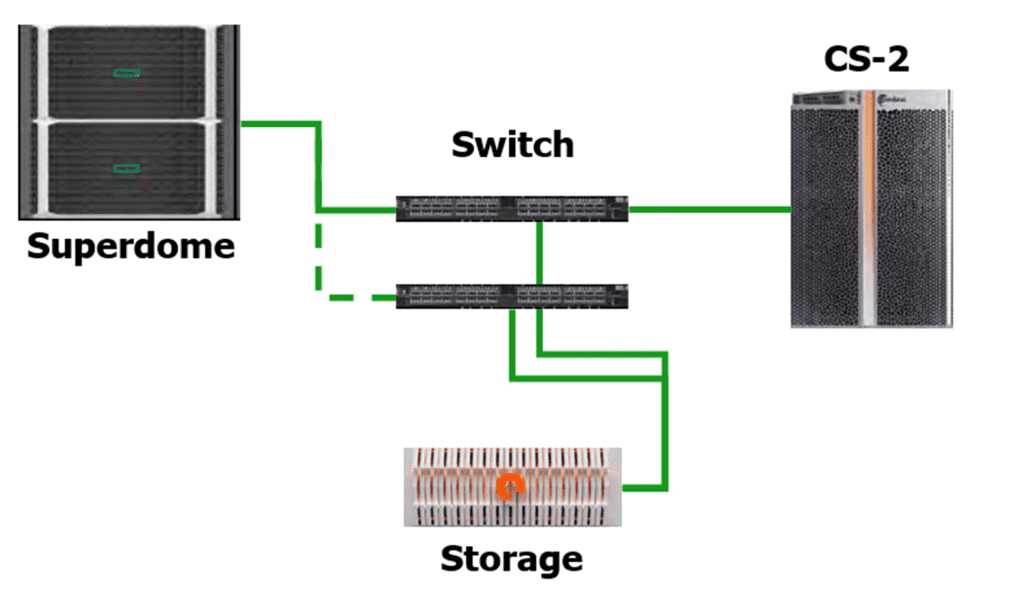
接続構成図
上記の構成で、自然言語のディープラーニングモデルのうち、巨大モデルであるBERT・GPTシリーズを実際に実行し、Superdome FlexとCerebrasを組み合わせた時のパフォーマンス比較等を行い、HPE様と巨大ディープラーニングモデルを処理するハードウェアの最適解を導き出したいと思っています。
結果については、PoC終了後にブログやオンラインセミナー等で発表させていただきたいと思います。
■Cerebras × Superdome Flexセミナー開催決定
最後に、弊社と日本ヒューレット・パッカード合同会社様でオンラインセミナーを行うことが決定しました。
今回ご紹介しましたSuperdome Flex とCerebrasとの新しいソリューション、そして、巨大ディープラーニングモデルの新たなアプローチなどのディスカッションも行われるそうですので是非ご参加ください。
開催日時は2022年11月8日(火) 11時~12時となっております。
お申込みはこちらのサイトからお願いいたします。
以上、いかがでしたでしょうか?検証結果もお楽しみに!
この記事をシェア