Cerebras Model Lab 大規模自然言語モデルのコスト試算ツール
みなさん、こんにちは
CerebrasプリセールスエンジニアのNakadaです。
今回、Cerebrasが提供するLLM (大規模自然言語モデル)のコスト試算ツールについて紹介します。
昨今、OpenAIが提供しているChatGPTを代表に、LLMを使った様々なサービスが登場しています。みなさんの中には、それらのサービスを既に利用されている方もいらっしゃると思います。
その中で、自社でLLMを構築することで自社の機密データを外部に出すことなく、生成AIを使ってみたいと考えたこともあるかと思います。ただ、LLMを構築する際に実際にどのくらいのGPUや時間が必要なのかとお悩みの方もいらっしゃると思います。
そのような方のために、無償で簡単に利用できるCerebras Model Labツールをご紹介させていただきます。
■Cerebras Model Labとは
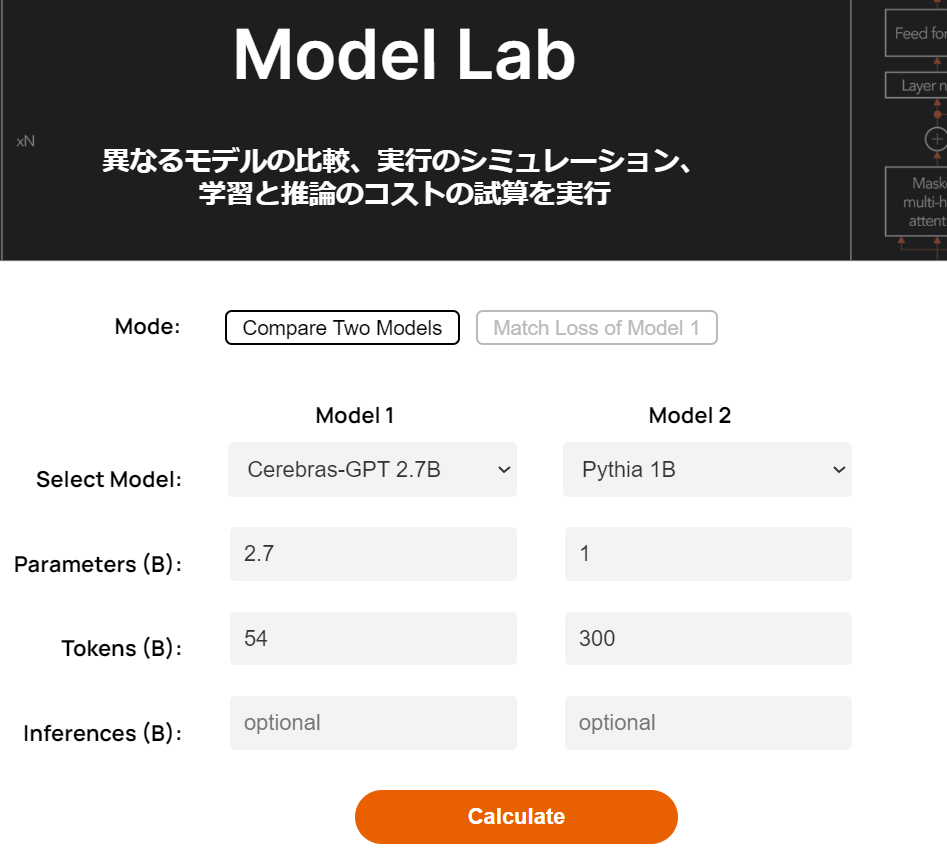
Cerebras Model Labは、Cerebras社が自身のサイトで公開しているツールです。以下が実際の画面となり、URLは「https://www.cerebras.net/model-lab/」でアクセスできます。
画面構成は非常にシンプルで、2つのモデルを比較する「Compare Two Models」と、対象モデルの精度と同じに達するまでに必要な学習量をシュミレーションできる「Match Loss of Model 1」があり、これらを使ってユーザは簡単にコスト試算ができるツールとなっています。このツールを使うことで、使いたいLLMモデルがどのくらいの精度が期待できるのか、学習に必要な計算量はどのくらいなのか、必要情報を入力し、Calculateボタンを押すだけで試算してくれます。
Model Lab設定入力画面 ※出展https://www.cerebras.net/model-lab/
■使い方
使い方は非常にシンプルです。まず、モードを選択します。

| Compare Two Models | 選択した2つのモデルを比較できます。 |
| Match Loss of Model | 選択したModel 1に入力したモデルに対し、Model2に入力したモデルがModel1と同等の性能(loss)に達するために必要なトークン数等を算出できます。 |
次にModel1とModel2に必要な情報を入力します。入力箇所はModel1とModel2とも以下の4つです。
| Select Model |
対象のモデルを選択します。約30種類の自然言語モデルとCustom(自由設定)が選択できます。 |
| Parameters(B) | Select Modelで選択したモデルのパラメータ数が入力されますが、自由に値を変更可能です。なお、単位はBillion(10億)です。 |
| Token(B) | Select Modelで選択したモデルに必要なトークン数が入力されますが、自由に値を変更可能です。なお、単位はBillion(10億)です。※必要なトークン数とはChinchilla式スケール則をベースに導かれた、学習精度に必要なトークン数です。 |
| Inferences(B) | 入力は必須ではありませんが、選択したモデルの推論時のコストを算出することが出来ます。なお、単位はBillion(10億)です。 |
必要な情報を入力したら、以下のCalculateボタンを押します。

結果は、以下のようにResults、Total Compute Cost、Loss Curveの3つが表示されます。
■「Compare Two Models」、「Match Loss of Model」結果の内容について
非常に簡単な操作で利用することが出来ますが、結果の内容についても説明します。基本的には記載されている項目の通りですが、それぞれのモードで実行した結果を元に解説します。
1.Compare Two Models
例として、以下を入力した場合です。
Model1には「Cerebras-GPT2.7B」を、Model2には「LLaMA 7B」を選択しました。Parameters(B)とTokens(B)の値は自動入力されています。
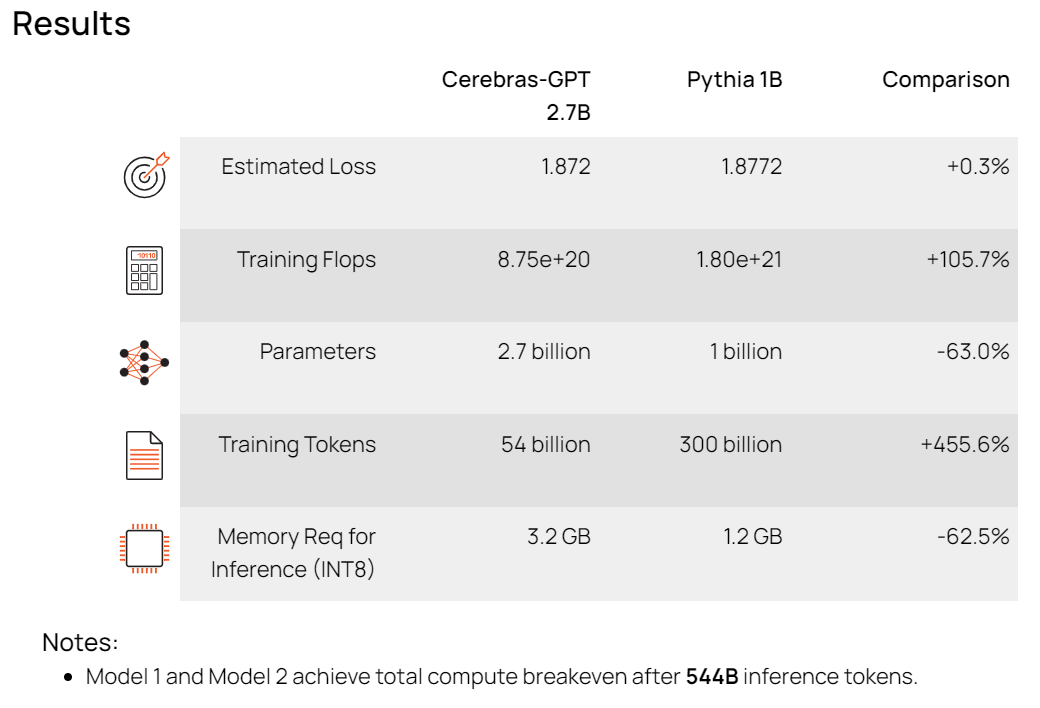
まず、Resultsですが、以下のように表示されました。
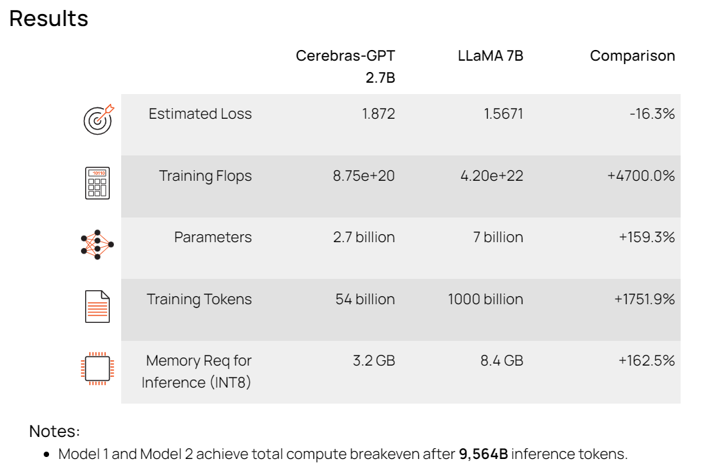
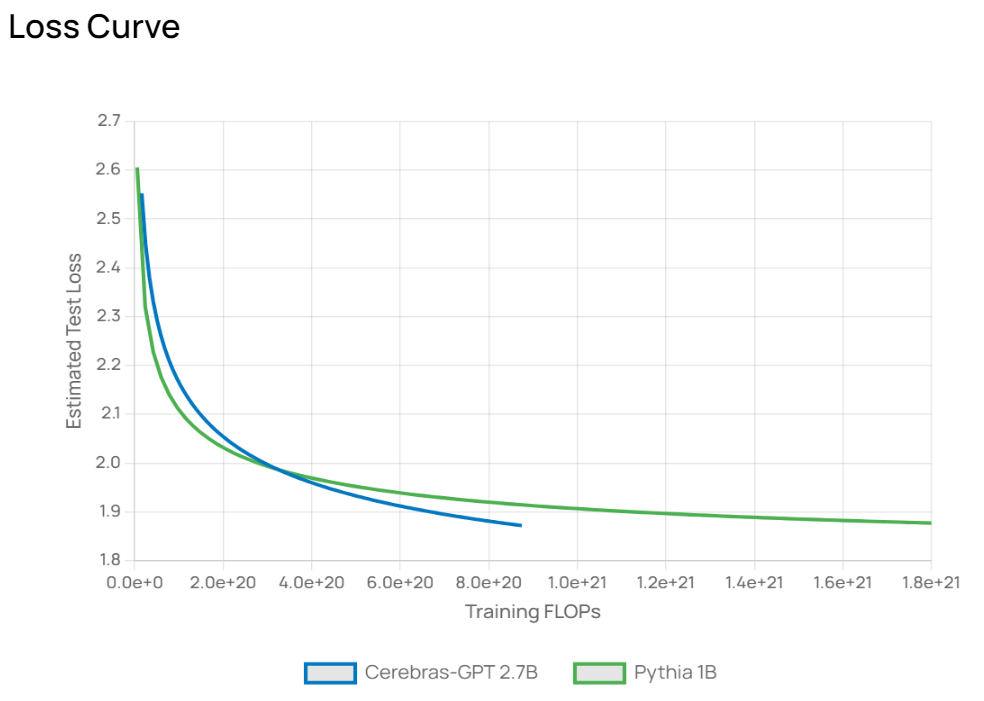
Estimated LossはそれぞれのモデルでToken(B)に入力されたトークン数を学習させた場合に到達予定のLoss値(損失値)です。
Training FlopsはそれぞれのモデルでToken(B)に入力されたトークン数を学習するために必要な計算量です。この値から必要なGPU数と学習時間などを見積もることが出来ます。
今回の場合、Model1はCerebras-GPT2.7Bですが、値は「8.75e+20」と指数で表示されており、875エクサフロップスの計算量が必要と見積もられています。この値からお使いのGPU、または購入予定のGPUのFLOPS性能を元に計算時間などを導くことができます。
ParametersはそれぞれのモデルでParameters(B)に入力されたパラメータ数をそのまま表示します。
Training TokensはToken(B)に入力されたトークン数をそのまま表示します。
Memory Req for inference(INT8)はそれぞれのモデルをINT8で推論実行する際に必要な推定メモリ容量を表示します。指定のモデルで推論(文生成)する際にどのGPUを利用するかの参考になります。
Notesは、結果の備考が表示されます。
なお、結果には一番右の項目にComparison(比較)があり、2つのモデルのそれぞれの結果項目に対する比が表示されます。
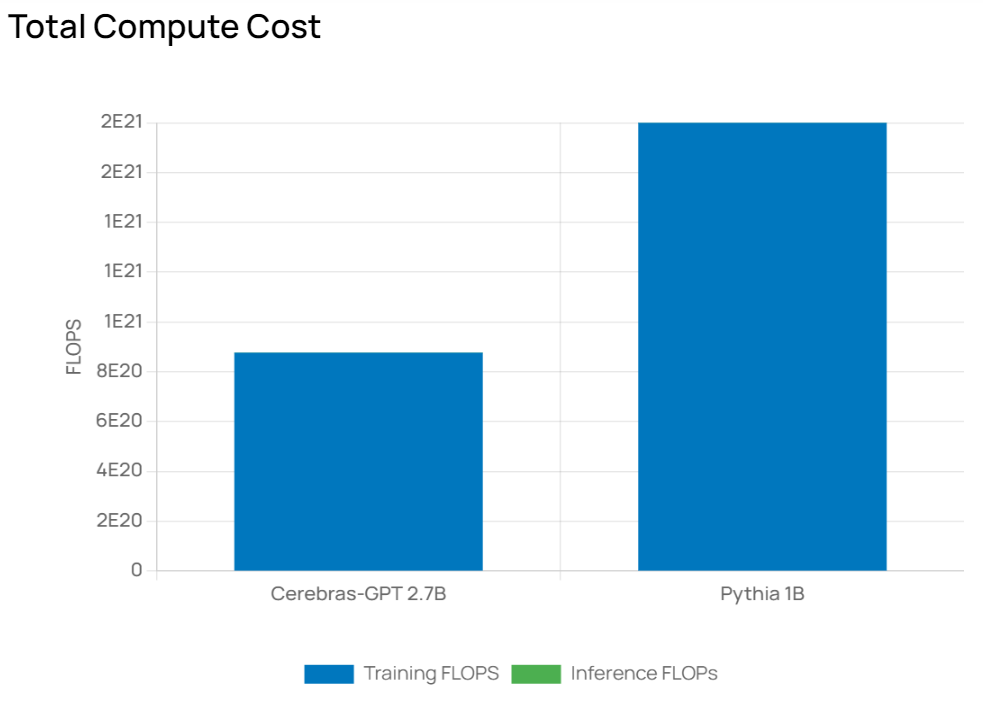
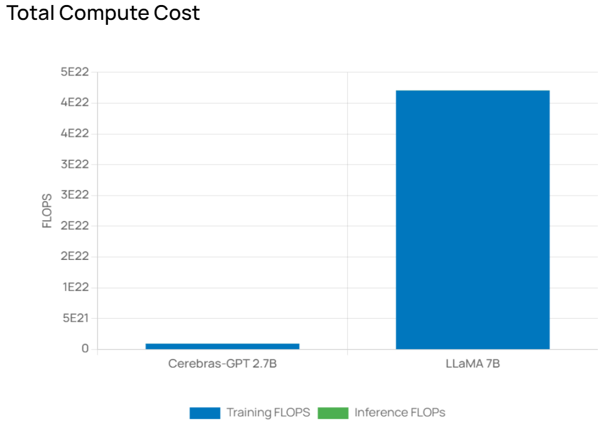
次にTotal Compute Costですが、こちらはResultsのTraining Flopsをグラフ化した結果が表示されます。Inferrence FLOPsは入力画面のInference(B)に値を入力すると選択したモデルの推論性能の予測値もグラフ化されます。
最後にLoss Curveですが、こちらはResultsのEstimated LossとTraining FlopsをベースにLoss収束の予測推移をグラフ化し表示します。
2.Match Loss of Model
例として以下を入力した場合です。
Model1には「Cerebras-GPT2.7B」を、Model2には「Cerebras-GPT 6.7B」を選択しました。Parameters(B)とTokens(B)の値は自動入力されています。なお、Model2側のTokens(B)は、値が入力されていますが、入力禁止になっています。これは、Match Loss of Modelは、Model2が、Model1の精度に達するまでに必要なトークン数を算出する機能なので、入力が禁止されています。

Resultsですが、以下のように表示されました。
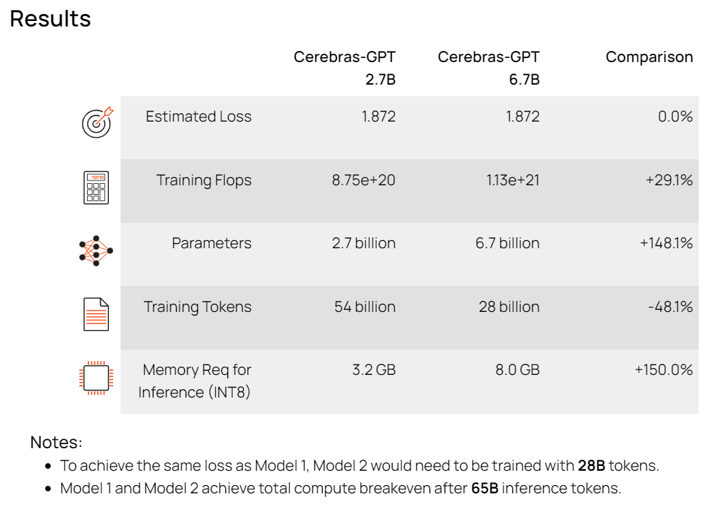
Estimated Lossは同じ値になります。これは、Match Loss of ModelはModel2がModel1の精度(Loss値)に達するまでのトークン数を算出するためです。Training Flops、ParametersはCompare Two Modelsと同様です。
Training Tokensが、Match Loss of Modelでは重要です。今回の結果は、Model1が「54 billion」でModel2が「28 billion」となっていますが、Model2がModel1と同様の精度に達するのに必要なトークン数は、Model1より少なくて良いという結果になります。
ただし、Training Flopsを見てください。
Model1は「8.75e+20」、Model2は「1.13e+21」です。計算量はModel2のほうが多いことになります。これはモデルのパラメータ数がModel2のほうが大きいからです。これから言えることは、大きいモデルは学習するトークン量が少なくても、小さいモデルの精度に達することができるということが分かります。ただ、トークン数が少なくても学習時間は小さいモデルよりも掛かってしまうので、これらのトレードオフを考慮しながら、利用モデルやデータセット量を選択するということになります。
最後に、Notesには「Model1 and Model2 achieve total compute breakeven after 65B inference tokens」とコメントが表記されています。これはAIモデルでは学習フェーズでGPUリソースを使いますが、LLMのように大規模AIモデルは推論フェーズでもGPUリソースを利用します。このコメントは推論フェーズでGPUリソースを利用した場合、学習フェーズ完了後に推論フェーズで65B(650億)推論トークンを処理するとModel1とModel2のそれぞれのトータル計算量が同じくらいになる(Breakeven=損益分岐点)ことを予想しています。ただし、言語モデルは様々なタスクに合わせたファインチューニングも必要ですので、ファインチューニング分のGPUリソースを入れるとこの予想は変わってきます。
Memory Req for inference(INT8)はCompare Two Modelsと同様です。
■最後に
今回は、大規模自然言語モデルのコスト算出ツールということで、Cerebras社のModel Labを紹介させていただきました。
このツールはChinchilla スケール則を元に再算出したCerebras-GPTスケーリング則の推定値を元に、各コストを算出しています。あくまで推定値ですので、学習実行前やモデル選択の際に参考情報としてご利用頂けると幸いです。
最後に、Model Labを公開しているCerebras社は世界最大のAIチップを開発した企業となっており、このAIチップ搭載したCS-2の販売や、CS-2をクラウド利用できるAI Model Studioサービスなども展開しています。Cerebras製品にご興味がある方は当社までお問合せ頂ければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア



