大規模言語モデルの最適化のためのDPO (前編)

東京エレクトロンデバイスでも、このような大規模言語モデルの学習に適した製品の取り扱いや、モデルの開発に取り組んでいます。
近年、OpenAIが発表したGPT4をはじめとする大規模言語モデルが注目を集めています。
これらのモデルは驚くべき能力を持ち、様々なタスクにおいて人間に匹敵する成果を上げています。東京エレクトロンデバイスでも、このような大規模言語モデルの学習に適した製品の取り扱いや、モデルの開発に取り組んでいます。
こうした流れの中で、近年AIの学習の関心領域が変化しつつあります。従来は自己教師あり学習によるモデルの汎化性能の向上が重視されていましたが、最近ではそうして訓練されたLLMから利用者の意図に沿った回答を引き出すといった目的が重視されています。
今回の記事では、DPO(Direct Preference Optimization)という手法について取り上げていきます。前後編に分けてDPOの原理や実用例、その他関連する情報についてご紹介します。DPOを活用することでAIがどのように変化するのか、興味深い視点が得られるかもしれません。是非、ご一読いただき、DPOの可能性について一緒に考えていきましょう。
おさらい -大規模言語モデル(LLM)について-
大規模言語モデル(LLM)は、近年注目を浴びている人工知能の一分野です。LLMは、機械学習と自然言語処理の技術を組み合わせ、大量のテキストデータから言語のパターンや文脈を学習し、それをもとに文章生成や自然言語理解のタスクを行います。
LLMは、その大規模な学習データによって高い予測精度を持つことが特徴です。一般的には数億から数十億のパラメータを持つモデルであり、トレーニングには膨大な計算能力とデータが必要とされます。
LLMの応用範囲は広く、自動翻訳、文章の要約、質問応答システム、文章の生成など、様々な分野で活用されています。例えば、自動翻訳では、LLMは大量の対訳データを学習し、言語間の翻訳を高精度で行うことができます。
しかし、LLMにはいくつかの課題もあります。まず、トレーニングには膨大な計算リソースが必要とされるため、ハードウェアやインフラストラクチャの整備が必要です。また、LLMは学習データに偏りがあると、その偏りを反映した誤った情報を生成する可能性があります。そのため、LLMの出力結果は常に注意が必要であり、人間の判断や修正が必要な場合もあります。
LLMのAligningの必要性
言語処理モデルのパラメータサイズの増加が精度向上に繋がることが分かっています。しかし、単にモデルを大規模させるだけでアプリケーションとして十分な能力が備わるわけではありません。実際には、いくつかの課題が存在します。
まず、信頼性の問題です。現行の言語処理モデルは、時折信頼性を欠く情報を提供することがあります。また、有害な情報を返したり、生成する情報が単に役に立たない場合もあります。つまり言語処理モデルがユーザーの意図を汲むことができず、提供される出力がユーザーが本当に欲している情報や回答に照らして十分な内容ではないことがあります。
現在、ベースモデルとして使用されるLLMは、インターネット上のウェブページの内容を元に、学習に用いる文章を模倣するような形での自己教師付き学習を事前学習として行っています。しかし、言語処理モデルの真の目的は、ユーザーの命令に従い、安全で有益な情報を提供することであり、必ずしも学習に用いた文章に似た文章を生成することではありません。
例を挙げるなら、LLMにプログラミング能力を学ばせるために敢えてコーディングミスを含むソースコードを学習させることがつまり、現状のLLMの学習目的とユーザーの要望の間には乖離があります。「ユーザーの命令に従った安全かつ有益な情報を提供する」という目的を達成するためには、その目的に沿った追加の学習が必要です。これを「Aligning」と呼びます。
Aligning手法としてのRLHF
ChatGPTやGPT-4で用いられているAlining手法としてRLHF (Reinforcement Learning from Human Feedback/人間からのフィードバックによる強化学習)があります。従来の強化学習では、エージェントは試行錯誤を通じて環境との相互作用を通じて学習しますが、RHLFではエージェントにあたるLLMが人間による選好情報をフィードバックとして受け取ることで学習の効率化や安定化が図られます。
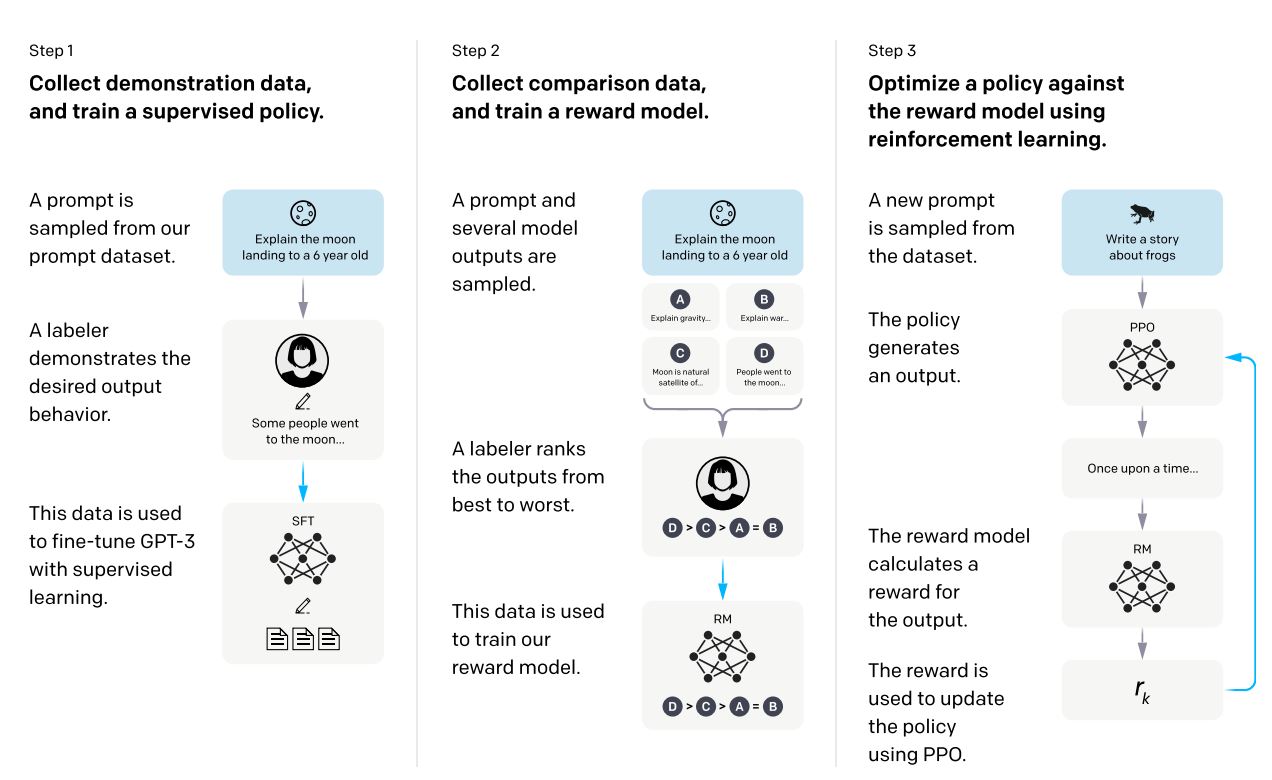 RLHFの概略図 https://arxiv.org/abs/2203.02155 より
RLHFの概略図 https://arxiv.org/abs/2203.02155 より
RLHFの基本的な仕組みは次のとおりです。
- SFTモデルの作成 – まず、任意のプロンプト(LLMに与えらえる指示文)と、そのプロンプトに対応する望ましい回答文(正解ラベル)のセットを複数作成し。これをデータセット化します。このデータセットを利用してLLMに教師あり学習(SFT)を行い、LLMの性能を補完します。
- 報酬モデルの作成 – 人間のフィードバックをもとに、LLMが受け取る報酬を算出するモデルを構築する工程です。最初に、SFTモデルにプロンプトを与え、複数の出力をサンプリングします。次に、人間によって、これらの出力を最も優れたものから最も悪いものまでランク付けします。最後に、このランキングデータを使用して報酬モデルをトレーニングします。報酬モデルは、SFTモデルが生成する文章を人間の選好に基づいてスコアリングするために使用されます。
- 報酬モデルを用いたSFTモデルの強化学習 – 報酬モデルを使用してSFTモデルの学習を進める工程です。用意したプロンプト文をSFTモデルに与え、得られた出力文の報酬スコアを報酬モデルを用いて算出します。そして、この報酬スコアを最大化するようにSFTモデルのフィッティングを行います。
RLHFは、実世界の複雑なタスクにおいて効果的な学習手法として注目されています。人間の知識や経験をフィードバックとして取り入れることで、学習の効率性や安定性が向上し、実用的な応用が期待されています。
DPO
上記のようにポリシー最適化やAligningに利用されているRLHFですが、目的となるLLMとは別に報酬モデルを用意する必要があることから、複数の課題を抱えています。複数のモデルを利用するということは演算コストの増大に繋がり、またモデルアーキテクチャの複雑化をもたらします。複数のモデルのハイパーパラメータ調整を行い適切にチューニングを行うことは多大な労力を要します。
こうした課題を軽減すべく最近発表されたAligning手法がDPO (Direct Preference Optimization)です。DPOはその名の通り、目的となるモデルに対して選好(Preference)による最適化を直接施すことのできる手法です。
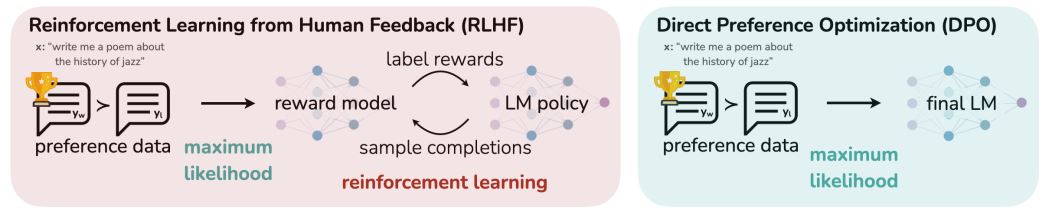 DPOの概略図 https://arxiv.org/abs/2305.18290 より
DPOの概略図 https://arxiv.org/abs/2305.18290 より
RLHFは以下の式についての最適化を行っています。r_Φ(x,y)が、プロンプトxについてLLMが回答yを出力した場合に報酬モデルが与える報酬の値を表す報酬関数です。
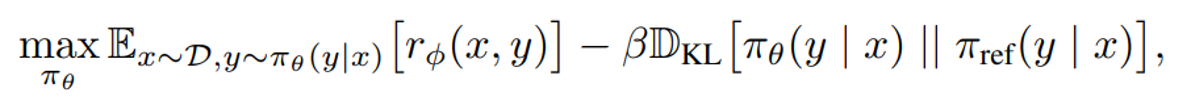
DPOは、この報酬関数の最適解rを、以下のように最終的な目的となるモデルπ_rの式で表すことができる点を利用しています。
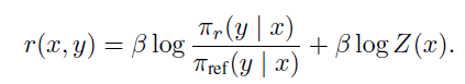
この報酬関数を、Bradley-Terryモデルという二つのプレイヤーの内の一方が勝つ確率を表す確率モデルに適用することで、LLMに人間の選好を模倣させる問題を以下の最適化問題として扱うことができます。
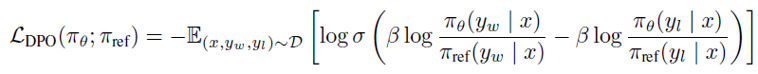
この数式で注目すべきは、報酬関数rが含まれていない点です。SFTモデルである π_θを最適化してπ_rに近づけていくことによって、暗黙的に報酬関数rの最適化をも行うのがDPOという手法であり、報酬モデルの個別の学習を省略できるのはこのためです。
ここまでで、LLMにおけるAligningの必要性と、その手法であるDPOについて説明しました。次回の後編では、実際にAI labを利用したDPOによるLLMのポリシー最適化を行った結果を紹介する予定です。
最後に、この記事の大部分の文章はexaBaseを利用して生成したものです。東京エレクトロンデバイスではLLMの事前学習からAIインフラストラクチャーの提供、アプリケーション開発や利用効率化まで幅広くカバーしております。企業での安全なchatGPT利用に興味がありましたら、是非exaBaseの利用を検討いただければ幸いです。
exaBaseについての詳細はこちら>>https://cn.teldevice.co.jp/maker/exaenterpriseai/
大規模言語モデルの最適化のためのDPO 実践編 (中編)はこちら>>https://cn.teldevice.co.jp/blog/p62072/
この記事をシェア