Cerebras CS-3を使ったLLM高速推論について

みなさん、こんにちは
CerebrasプリセールスエンジニアのNakadaです。
これまで、ブログにて大規模自然言語モデル(以下、LLM)の学習にフォーカスした内容を紹介させていただきました。今回はCerebras社が開始したLLMの高速推論サービスをご紹介します。
LLM高速推論の必要性
生成AIサービスを利用する際に、一番多い使い方はチャットボットではないでしょうか。チャットボットで1つ質問をして1つ回答を得るだけであれば、特にストレス無く利用できていると思いますが、望んだ回答では無い場合は、聞き方を変えて更に必要な情報を追加して質問する場合もあると思います。それが複数回続くと回答の生成スピードにストレスを感じた経験はないでしょうか。また、「○○について10個の例を挙げてください」や「○○について1,000文字で作文してください」など、回答に長文を求める際も生成スピードにストレスを感じることがあると思います。
AIと会話できるインターフェース開発も進んでおり、ロボットと会話するというシーンをテレビなどで見たことがある方もいらっしゃると思います。実際の人と人との会話では、数百ミリ秒の応答遅延があると会話が途切れたようになり、会話が不自然に感じられるそうです。現在のAIとの会話技術にはLLMがベースとなっているのものあり、応答スピードの重要性が増します。
最近では、生成AI・LLMを使った多種多様なサービスが開発されていますが、動画生成ツールでもLLMが使われており、動画内の仮想の人物がしゃべる内容をLLMが生成し、動画に自動で挿入しているそうです。この時にもLLM生成スピードは重要で、生成が遅いと動画の口の動きと合わないという現象が起きたりするそうです。
このように、生成AIの利用範囲が広がるにつれて、分野によってはLLMの高速推論が必要となってきています。
Cerebrasの高速推論について
Cerebrasはアメリカのスタートアップ企業です。AI/ディープラーニングの利用に欠かせないものにGPUがありますが、GPUとは異なる、AI処理に有効なデータフローアーキテクチャをベースに開発した超巨大チップ「WSE」を搭載しているAIアクセラレータ「Cerebras CS-3」を販売している会社です。

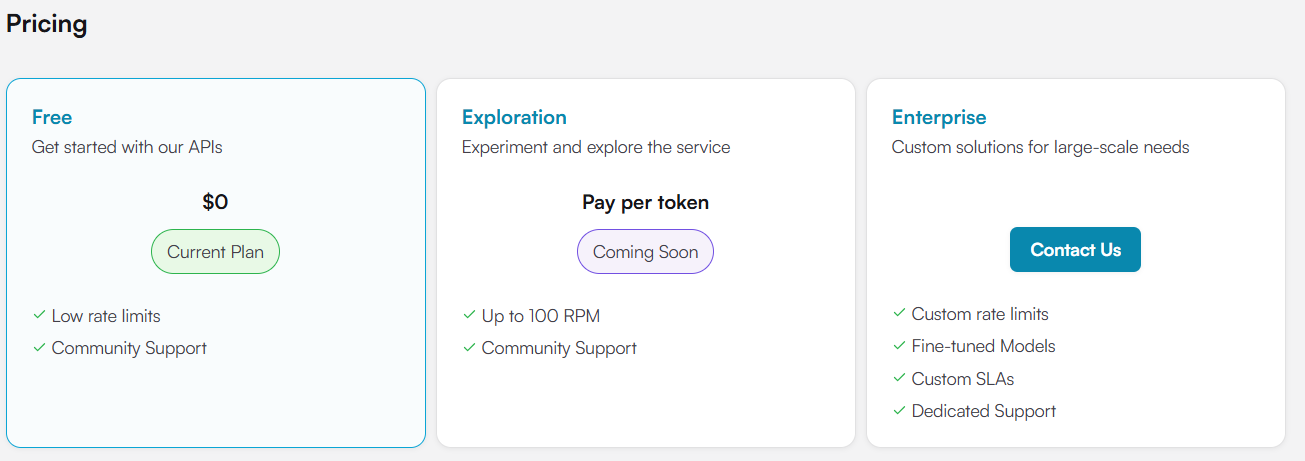
Cerebrasは当初、超巨大チップを使ったAIのトレーニング処理に特化した製品でしたが、LLMの高速推論のニーズが高まり、Cerebras CS-3を使った高速推論サービスを開始しました。現在、制限はありますが無償でも利用が可能です。
出典:Cerebras Experiment with our inference solution in the playground
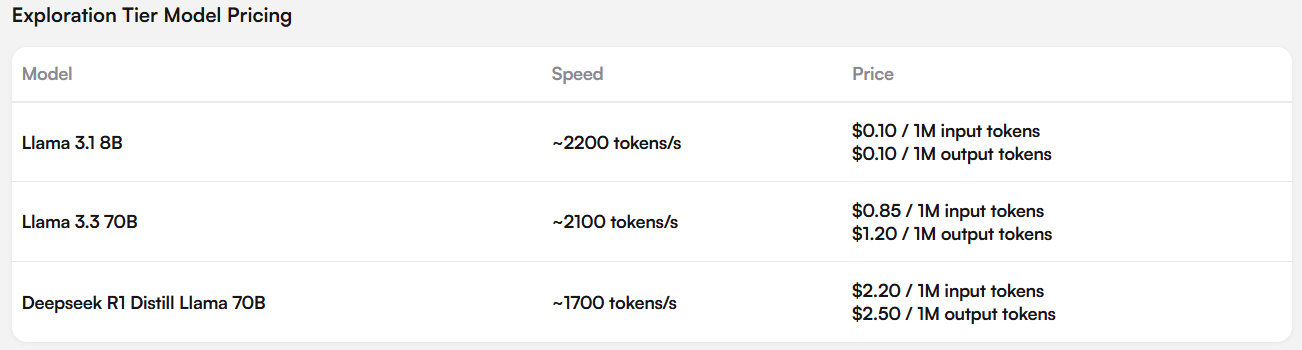
無償版の制限を無くした有償版としてはExplorationティアとして従量課金制があり、さらに大規模なニーズに対応するカスタムソリューションとして月額定額制(3ヶ月、6ヶ月、12ヶ月契約)もしくは従量課金制で契約となるEnterprise契約もあります。
出典:Cerebras Experiment with our inference solution in the playground
CerebrasのLLM高速推論のパフォーマンスについて
実際のLLM高速推論のパフォーマンスですが、AI推論サービスのパフォーマンスを公表しているArtificial Analysis社のデータとして以下の結果が出ています。

この結果はMeta社のLlama3.1 405Bモデルの1秒当たりの生成トークン数です。他の推論サービスと比べ圧倒的な生成速度を達成していることが分かります。なお、生成速度は速いですが、冒頭でお話した人間の会話の遅延を考慮した場合、この性能でAIとの会話遅延は問題ないでしょうか?1秒間の生成トークンが多くても、最初の出力が遅延した場合、AIとの会話には不自然さが残ってしまいます。
以下のパフォーマンスは、最初のトークンが生成されるまでの時間です。こちらもCerebrasが圧倒しており、最初のトークンの生成には0.24秒と人との会話でも違和感のない遅延時間となっています。

実際に体験してみる
パフォーマンスについてグラフで説明しましたが、実際に体験したほうが分かりやすいです。Cerebras社はチャットボットとAI会話が体験できるデモサイトを公開しています。※注 Googleアカウント等での認証が必要です。
デモサイト: https://cerebras.ai/inference

「TRY CHAT」からチャットボットを試すことが可能です。利用できるLLMモデルですが、現在は「Llama3.1 8B」「Llama3.3 70B」「DeepSeek-R1-Distill-Llama-70B」の3種類です。話題のDeepSeekはLlama-70Bの知識蒸留モデルとなっています。日本語でも入力できますのでCerebrasの高速推論がどのくらい速いのか是非試してください。

なお、チャットボットの入力ウィンドウの下に「Try Voice Mode」というボタンがあります。こちらをクリックすると音声入力ができるモードが開きます。「START A CONVERSATION」ボタンを教えて会話してみましょう。
以下は会話中の画面ですが、最初に女性の声で「Hi there, How are you doing today!」とあいさつしてくれます。日本語はしゃべれなそうなので、英語で会話してみてください。応答のスピードも実際の人と会話しているようなスピードで応答してくれます。是非体験してみてはいかがでしょうか。
最後に
今回はCerebrasの高速推論について紹介させて頂きました。Cerebrasは2025年3月にこの推論環境を、新たに米国3拠点、カナダ1拠点、ヨーロッパ1拠点、CerebrasのパートナーであるG42に1拠点で、計6拠点のデータセンターに構築することを発表しました。
今回紹介した高速推論を利用する機会が増えるかもしれません。もしかすると日本に拠点が構築される日も遠くないかもしれません。最後に、このブログをお読みになり、LLMおよびAIアクセラレータ製品、高速推論等にご興味を持たれた方は、当社までお問い合わせ頂ければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア
