Datadog Walk | サーバーのリソース監視

操作画面や設定例を交えながら、実務で使える知識を解説していきます。
今回は、サーバーのリソース監視(CPU 使用率やメモリ利用状況など)をテーマに紹介。
メトリクスモニターの作成方法やしきい値設定を順を追って解説し、リソース不足の兆候をいち早く検知・対応するための基本的な監視の仕組みをまとめています。
はじめに
システムが安定して稼働し続けるためには、サーバーのリソース状況を把握することが欠かせません。
CPU 使用率やメモリ利用状況、ディスク容量などのリソース指標は、性能低下や障害の兆候をいち早く示してくれる大切なサインです。
Datadog を活用すれば、これらの指標を継続的に監視し、しきい値を超えたタイミングでアラートを受け取ることができます。リソース不足の予防やトラブルの早期解決につなげるために、基本となるリソース監視の考え方と実践方法を見ていきましょう。
メトリクスモニターの作成
Datadog では、サーバーのリソース状況を監視するために「メトリクスモニター」を作成します。
メトリクスモニターは、CPU 使用率やメモリ利用率などの特定のメトリクスに対してしきい値を設定し、その条件を満たした際にアラートを通知する監視設定です。
作成手順はシンプルで、監視対象とするメトリクスを選び、条件(しきい値・評価時間)、通知内容を設定する流れになります。
CPU使用率を監視するモニター作成を例に、ステップを踏んでみていきましょう。
- Datadog 管理UIから、Monitors > New Monitor をクリックします。
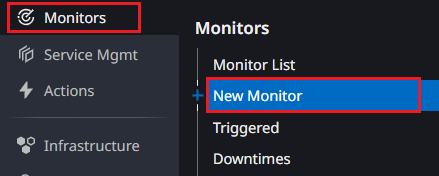
- 作成するモニタータイプの選択画面に自動で遷移します。
リソース監視ではMetric Monitorを利用しますので「Metric」をクリックします。
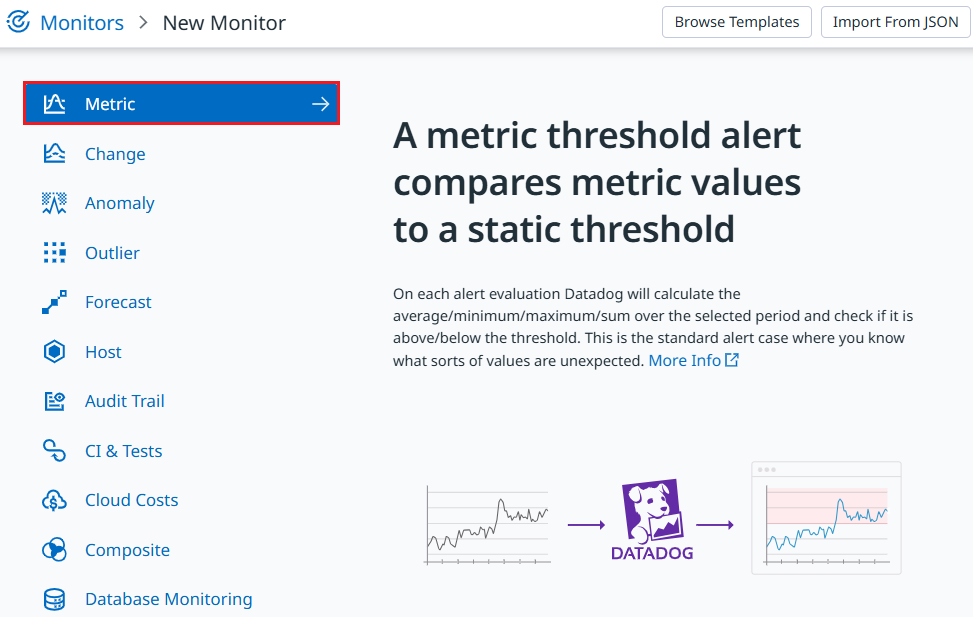
- モニター作成画面が表示されます。
はじめに「① Choose the detection method」欄で、モニターの検知ロジックを指定します。
今回は一般的に利用される Threshold Alert(Default)を選択します。

※各検出ロジックの概要
検出ロジック 概要 例 しきい値 (Threshold) 固定の数値を基準にして、上下限を超えたときにアラートを出す CPU 使用率が 90% を超えたらアラート 変化検出 (Change) 急激な増加や減少を検出し、通常の変動を超えた変動を検知 通常10件/分のログが、急に100件/分になったとき 異常検出 (Anomaly) 過去の傾向と比較して異常な変化を検知する 通常 20〜30% のCPUが急に 80% に上昇した場合 外れ値検出 (Outlier) 複数のホストやサービス間で異常な振る舞いをしている個体を検出 10台中1台のレスポンスタイムだけ極端に遅くなった場合 予測
(Forecast)時系列データから未来を予測し、しきい値を超えると予測された時にアラートを出す ディスク使用率の増加傾向から 24時間以内に満杯と予測された場合 自動検出 (Watchdog) DatadogのAIが自動で異常を検知 過去の傾向と比較して異常な値を示した際に自動アラート発生 - 次に「① Define the metric」欄で、メトリクス、範囲(Scope)、集計(Aggregation)の指定を行います。いくつかの要素があるため、1つずつ説明していきます。
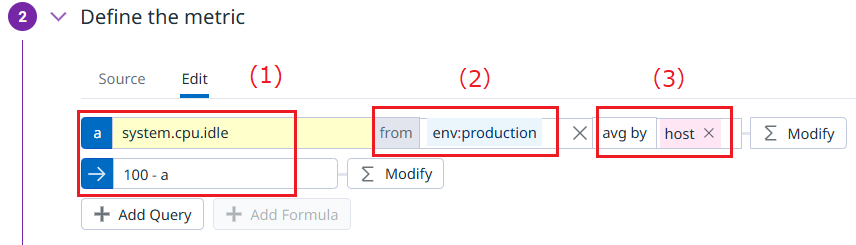
(1) メトリクス – Metric
今回はCPU使用率に関連するメトリクスとして、CPUのアイドル率(%)を示す「system.cpu.idle」を指定します。Add Formulaボタンをクリックし100からアイドル率を引くことでCPU使用率(%)を算出します。(2) 範囲 – Scope
メトリクスを評価する対象を絞ることができます。今回の例ですと、env:production タグをもつホストに限定しています。Defaultでは指定なしです。
(3) 集計 – Aggregation
ここがイメージしにくいのですが、メトリクス(数値データ)を、どのような単位で集めて評価するかを決める設定になります。
まず、集計方法には次の4つがあります。
・avg by
・max by
・min by
・sum by例えば、ホスト10台が監視対象となる場合で集計単位の指定をしないと、評価値が次の表のようになります。
集計方法 単位 評価値 avg by 指定なし ホスト10台分のCPU使用率の平均値 max by 指定なし ホスト10台分のCPU使用率の最大値 min by 指定なし ホスト10台分のCPU使用率の最小値 sum by 指定なし ホスト10台分のCPU使用率の合計値 単位にhostタグを指定すると、ホストごとに集計されるようになります。
1台のホストで収集されるCPU使用率のメトリクスは1つのみとなるため、どの集計方法を指定しても集計結果は変わらず、ホストごとのCPU使用率 が評価値になります。
ホストごとに1つのメトリクスしかないため、平均・最大・最小・合計を取っても同じ値になるということです。
集計方法 単位 評価値 avg by host ホストごとのCPU使用率 max by host ホストごとのCPU使用率 min by host ホストごとのCPU使用率 sum by host ホストごとのCPU使用率 ここでは、ホストごとにCPU使用率のしきい値監視をしたいため、集計単位にはhostタグを指定しています。集計方法は何を選択しても変わらないため、Defaultの avg by のままとしています。
- Evaluation Details 欄では、例えば「直近XX分間の平均値」など、最終的に評価に使用される数値の算出方法を指定します。Defaultは「直近5分間の平均値」です。

- 「③ Set alert conditions」にて、具体的なしきい値を指定してきます。
Alertのしきい値は必須、Warningのしきい値はオプションになります。
ここでは、80%以上の場合はWarning、90%以上の場合はAlertとしています。
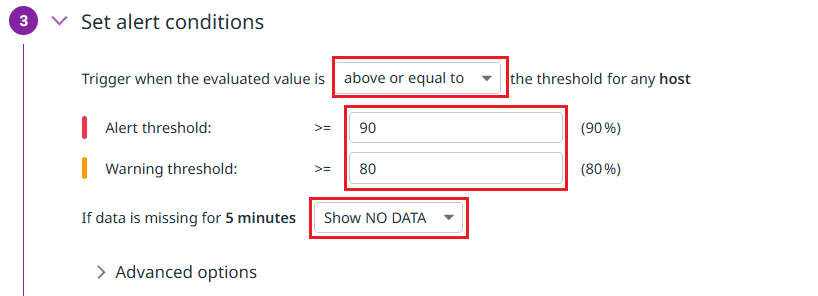
また、「If data is missing for ~」にて、Agentから対象のメトリクスが収集されていない場合のモニターステータスを指定します。
Default は Show last known status です。指定 メトリクス収集が停止している場合のモニターステータス Show last known status 収集が停止する直前のステータス Show NO DATA NO DATA Show NO DATA and notify NO DATA(且つ通知可能にする) Show OK OK NO DATAとなるのは主にAgentがダウンした状況が想定されますが、各モニターでNO DATA通知を設定した場合、Agentダウンで各モニターからNO DATA通知が発砲されることになり、大量のメールが届く形になります。何か起こったことは分かりますが、肝心のAgentダウン=死活監視モニター通知が埋もれてしまう懸念があります。まずは Show NO DATAとして、NO DATA 検知は日々のモニターステータス(ダッシュボード)で確認する、という方針も考慮頂くとよいかと思います。
- 以降は、通知内容の設定、プライオリティなどのメタ情報付与、およびモニター編集権限の指定 と他のモニター作成時の手順と変わりません。参考までにCPU使用率の監視モニターの通知内容の例を記載します。

リソース監視の主要メトリクス
サーバー監視では、CPU・メモリ・ディスク・ネットワークといった基本的なリソースの利用状況を数値化して把握することが欠かせません。これらのメトリクスをモニタリングすることで、性能劣化やリソース不足といった問題を事前に察知できます。以下の表では、サーバーのリソース監視でよく利用される主要メトリクスを整理しています。
| 監視対象のリソース | メトリクスと数式 |
| CPU使用率 (%) | 100 – system.cpu.idle |
| メモリ使用率 (%) | (1 – system.mem.pct_usable) * 100 |
| ネットワーク帯域使用 (Mbps) ※送信 | system.net.bytes_sent * 8 / 1000000 |
| ネットワーク帯域使用 (Mbps) ※受信 | system.net.bytes_rcvd * 8 / 1000000 |
| ディスク使用率 (%) | system.disk.in_use * 100 |
通知内容に変数 {{threshold}} {{warn_threshold}} を利用することを考慮して数式を入れています。
まとめ
サーバーのリソース監視は、安定したシステム運用を支える重要な取り組みです。
CPU やメモリ、ディスクなどの使用状況を定期的にチェックし、しきい値を超えた際にアラートを受け取れる仕組みを整えることで、問題を未然に防ぎ、トラブル発生時にも迅速に対応できます。
Datadog のメトリクスモニターを活用すれば、こうした監視をシンプルかつ効果的に実現可能です。ぜひ日々の運用に取り入れて、より安心できるシステム基盤づくりにつなげていきましょう。
Datadog Walk では、このように実際の画面操作や設定例を交えながら、監視運用に役立つポイントを一歩ずつ整理していきます。
※ 当社の取り組み
Datadogを始めてみたい!という方は東京エレクトロンデバイスでDatadog製品の紹介から技術支援まで対応させて頂ければと思いますので、是非こちらからお問合せ頂ければと思います!
※ 注記
当ブログのコンテンツ・情報について、できる限り正確な情報を提供するように努めておりますが、正確性や安全性を保証するものではありません。情報が古くなっていることもございます。
当サイトに掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。

この記事の投稿者Takashi Tanaka
現在はDatadog製品の提案・構築に従事。
経歴としてはNAS、Backup、サーバー、仮想化とオンプレインフラ周りのエンジニアを歴任してきました。
子育て奮闘中です。
この記事をシェア