Cerebras-CS2で大規模言語モデルを3日で作ってみた

最近すっかり定着してきた感のあるChatGPT、利用されている人も多いのではないでしょうか?
このChatGPTを支えるのが大規模言語モデル(Large Language Model:LLM)と呼ばれるディープラーニングモデルです。
自然言語処理のディープラーニングでは、非常に巨大なニューラルネットワークのモデルを作る必要があり、モデル作成に数か月を要することもあります。このため、学習するマシンのメモリ量や計算速度がとても重要です。
当社のTED AI Labでは、ディープラーニング専用の超高速マシンCerebras CS-2を活用できる環境を提供しています。この世界最速級のマシンがすぐに使える!ということで、今回はBERT Largeのアルゴリズムを使って事前学習を行いその処理速度を体感してみました。
Cerebras CS-2って?
Cerebrasは世界最大の巨大チップを備えたディープラーニング専用のネットワークアタッチドアクセラレータ(=ネットワーク上にあるアクセラレータ)です。
ディープラーニングのサーバーと言えば、GPUサーバーを思い浮かべる人が多いと思いますが、Cerebrasは一般的なGPUとは異なりサーバーとGPUチップを分離して、GPUチップ部分のみシステムとして利用します。これにより、巨大チップをサーバーに搭載することなく、GPUよりも膨大な量の処理を超高速に処理することができます。
ただ、その代わりにデータを送信するサーバーが必要です。TED AI Labでは計9台のサーバーがスタンバイしています。(下図)Worker1サーバーでプログラムを実行すると、Worker1がChiefノードとして、Worker2~9はInput Workerノードとして動作します。また、各WorkerサーバーはCerebrasの Singularityコンテナが起動して制御できる構成になっています。
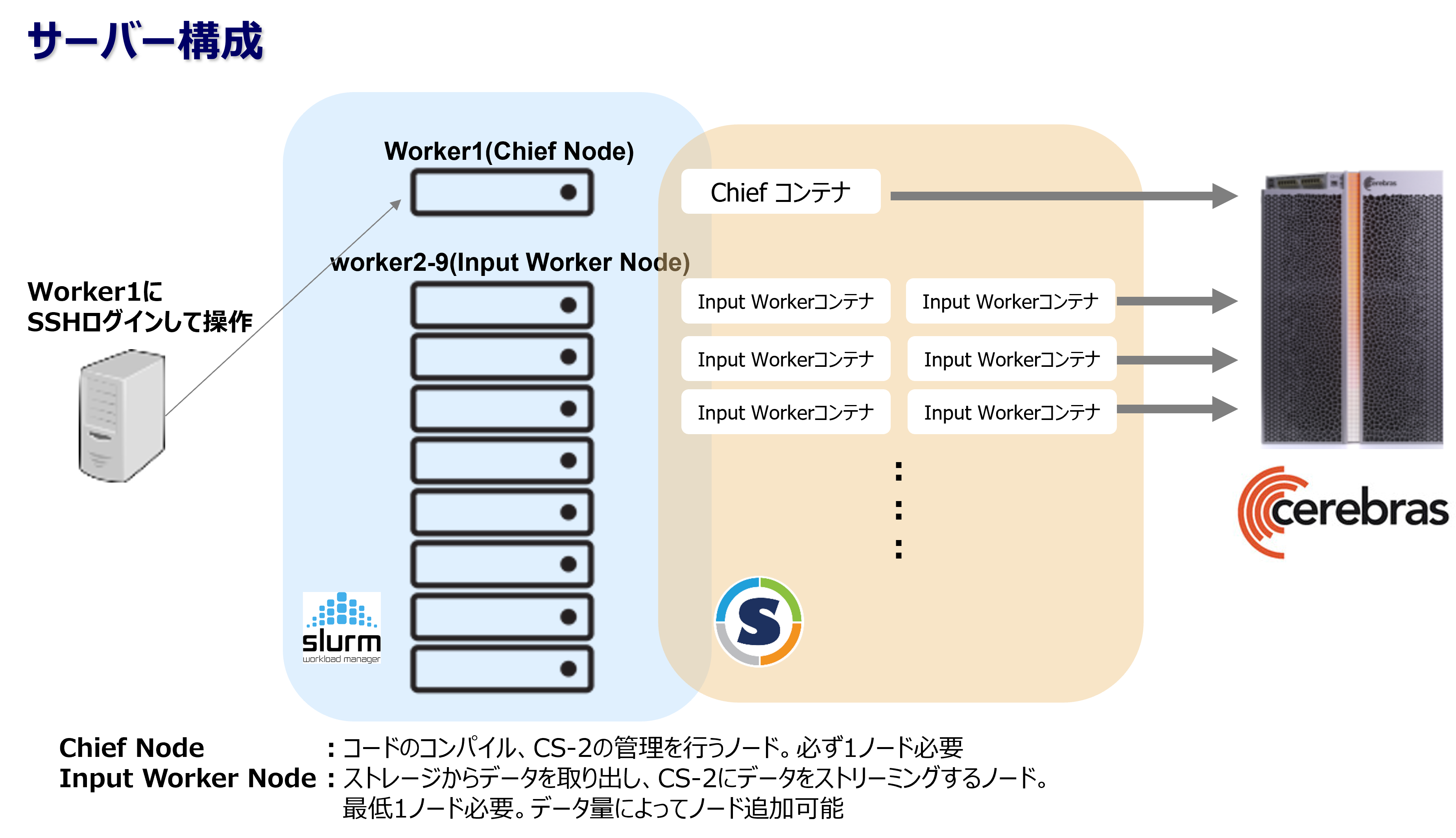
※この構成はOriginal Cerebras Installation構成のものです。
データセットの準備(前処理)
まずは、CS-2でモデル作成するためのデータセットを準備します。
今回は、日本語データセットとして、Wikipediaの日本語版データセットを準備しました。元のテキストファイルは約1412万行、11億文字のデータで、3GBのデータになります。
このデータセットを元に、Cerebras CS-2の学習に必要な①語彙ファイルと②学習・検証用のデータセットを作成していきます。
① 語彙ファイルの作成
語彙ファイル((Vocabファイル)は、文章を単語(トークン)ごとに分割したファイルです。分割するためのトークナイザープログラムが各種公開されていますので、今回は日本語にも対応した「SentencePiece」を利用して語彙ファイルを作成しました。
URL: https://github.com/google/sentencepiece
② 学習・検証用データセットの作成
次に、CS-2に学習させるための学習用データセットと学習精度を確認するための検証用データセットを作成します。ちなみにCerebras CS-2では、PyTorchやTensorflowのpythonライブラリを利用できますので、既に前処理したデータセットがあればそのまま使うことができます。
今回は、元の日本語Wikiデータセットを学習用と検証用のデータセットに以下のように分割した後に、Tensorflowがサポートするデータセットフォーマットであるtfrecord型に変換しました。
- 学習用データセット:14,120,000行(※)
- 検証用データセット: 6,174行
※ 学習用データはメモリエラー回避のため更に5000行単位にファイル分割
Cerebras CS-2には、Cerebras Modelzooサンプルコードというディープラーニングのモデル作成で汎用的に利用できるサンプルプログラムが準備されています。テキストファイルからtfrecord型に変換するプログラム (create_tfrecords.py)も用意されていますのでこれを使ってみます。実行すると出力フォルダにtfrecordファイルが出力されます。
[実行例]
python create_tfrecords.py
--metadata_files metadata_file.txt
--input_files_prefix metadata_file_path
--vocab_file vocab.txt
--output_dir ./output_tfrecords
–-do_lower_case
--max_seq_length 128
--max_predictions_per_seq 20
–metadata_files:メタデータファイル(データセットのファイルパスを記載したファイル)
–input_files_prefix:データセットのフォルダパス
–max_seq_length : 学習時の入力シーケンス長(※)
–vocab_file:語彙ファイル(Vocabファイル)
–output_dir:出力フォルダ
※ 学習時の入力シーケンス長(MSL)は、学習時に1つの文章として学習する単語数のことです。 今回は学習用と検証用でそれぞれMSLが128単語と512単語の2種類のシーケンス長のtfrecordを作成、以下計4種のデータセットを準備しておきます。
- 学習用データセット(MSL128)
- 検証用データセット(MSL128)
- 学習用データセット(MSL512)
- 検証用データセット(MSL512)
Cerebras CS-2で学習モデル作成
データセットの準備ができたらいよいよ大規模言語モデルの作成です。
データセット変換プログラムと同様に、Cerebras modelzoo サンプルコードには、CS-2対応のディープラーニングモデル(下表)で学習するためのプログラム(run.py)がそれぞれ準備されています。今回はBERTモデルの実行プログラムを使います。
[Cerebras対応のディープラーニングモデル] 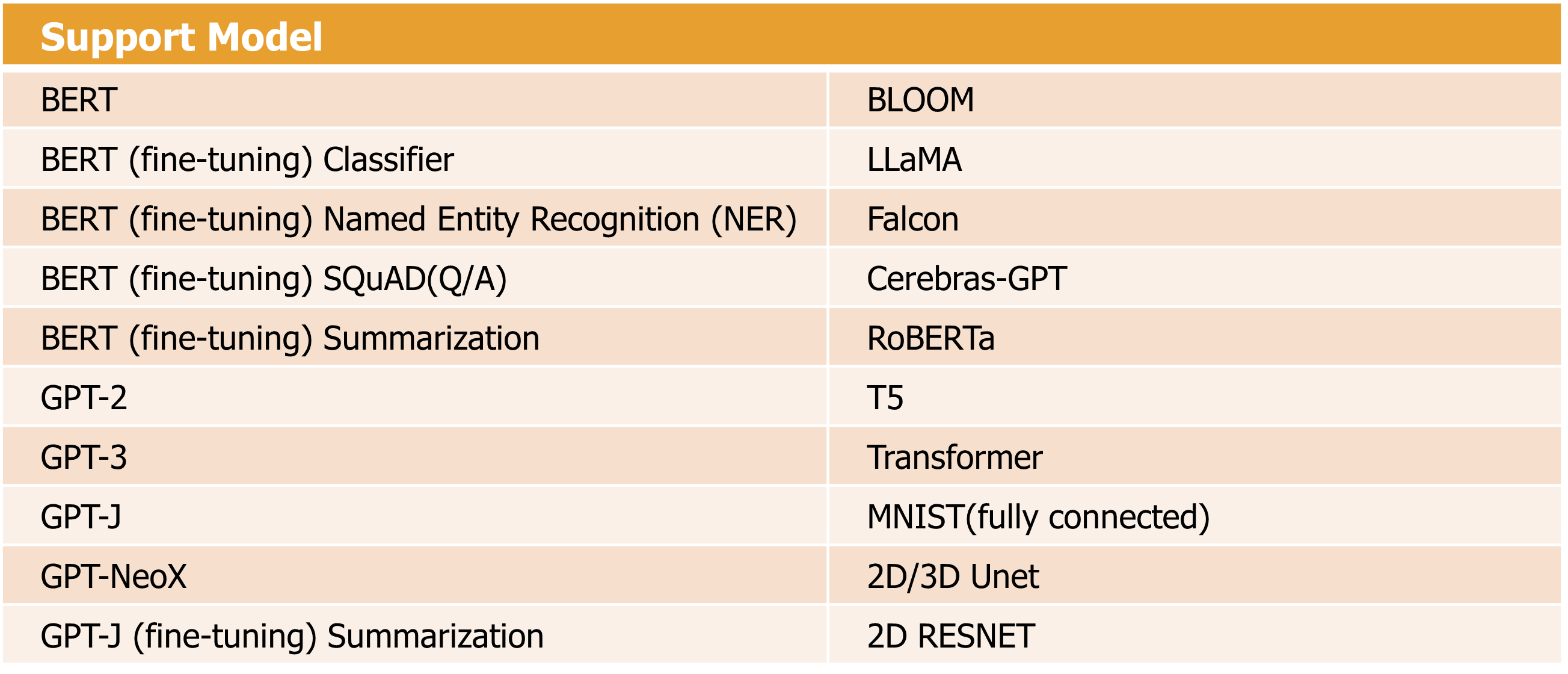
CS-2でのモデル作成は、csrun_wseコマンドとrun.py実行で行うことができます。csrun_wseコマンドにより、各workerサーバー上でCerebras Singuralityコンテナが起動して処理を行います。
[実行例]
csrun_wse python run.py
--mode train
--cs_ip 192.168.0.XX
--params ./configs/params_bert_large_msl128.yaml
--model_dir ./model_msl128
–mode:学習(train)と検証(eval)のモード選択
–cs_ip:Cerebras CS-2のIPアドレス
–param:configファイル
–model_dir:学習モデル出力先フォルダ
–paramで指定しているconfigファイルは、学習に使用するデータやパラメータ等の各種設定を行います。以下のようにデータセットの準備で作成した語彙ファイル、tfrecordデータセットのフォルダおよび入力シーケンス長(MSL)を指定します。
[configファイル抜粋]
:
train_input:
data_processor: BertTfRecordsProcessor
data_dir: '/mnt/Pure_Vol2/wiki_dump/bert/tfrecords/ja_train_14m_uncased_msl128'
vocab_file: '/mnt/Pure_Vol2/wiki_dump/vocab.txt'
max_sequence_length: 128
max_predictions_per_seq: 20 # maximum number of masked LM predictions per sequence. Fixed to 20 for now
batch_size: 256
buckets: [39, 56, 72, 89, 108] # should only be used with batch size 256
eval_input:
data_processor: BertTfRecordsProcessor
data_dir: '/mnt/Pure_Vol2/wiki_dump/bert/tfrecords/valid_3k_uncased_msl128'
vocab_file: '/mnt/Pure_Vol2/wiki_dump/vocab.txt'
max_sequence_length: 128 # fixed to 128 for LM for now
max_predictions_per_seq: 20 # maximum number of masked LM predictions per sequence. Fixed to 20 for now
batch_size: 256
:
BERTアルゴリズムでは、短文のデータセットで学習した後、長文のデータセットで学習を行うことによって、モデルの精度を維持したまま学習時間を短縮する手法があります。今回は、データ準備で短文用のMSL128と長文用のMSL512の学習・検証用のデータセットを準備していますので、それぞれのデータセットに対してrun.pyを実行して学習と検証を行いました。
その他にもconfigファイルではディープラーニングに必要なハイパーパラメータを指定することができます。必要に応じてチューニングすることができますが、今回はデフォルトの設定で実行してみます。
[configファイル抜粋]
### Optimization
optimizer:
optimizer_type: 'adamw' # {'sgd', 'momentum', 'adam', 'adamw'}
weight_decay_rate: 0.01
epsilon: 1e-6
max_gradient_norm: 1.0
disable_lr_steps_reset: True
learning_rate:
- steps: 10000
scheduler: 'Linear'
initial_learning_rate: 0.0
end_learning_rate: 0.0001
- scheduler: 'Linear'
initial_learning_rate: 0.0001
end_learning_rate: 0.0
steps: 1000000
loss_scaling_factor: 'dynamic'
プログラム実行後は、Slurmがジョブ管理を行い、必要に応じてworkerサーバーのCerebras Singularityコンテナを起動してCS-2にデータを送信します。Slurmのジョブはsqueueコマンドで確認することができます。
[実行例] 
実行例ではWorker1と2のサーバー上でCerebras Singuralityコンテナが起動し処理が進行していることが分かります。あとは処理が終わるのを待ちます・・・
モデル作成結果の確認
モデル作成が完了したら、モデル作成の結果を確認してみましょう。
MSL512の検証用データセットでの検証結果出力ログを確認すると、モデル精度は約95%と高い精度でモデル作成できていることが分かります。
[出力ログ抜粋]
user@worker1 bert]$ csrun_wse python run.py --mode eval --cs_ip 192.168.0.199 --params ./configs/params_bert_large_msl512.yaml --model_dir ./msl512
:
=============== Cerebras Compilation Completed ===============
Unable to find operator library: /cbcore/py_root/cerebras/tf/custom_ops/csrc/lib/online_norm/online_norm_gpu.so
:
TSKM201 16:12:34 Send block sizes:
TSKM201 16:12:34> pre-cliff: 256, post-cliff: 256; using send block size: 256
TSKM201 16:12:34> Receive block sizes:
TSKM201 16:12:34> pre-cliff: 2560, post-cliff: 2560; using receive block size: 2560
:
INFO:Tensorflow:global step 1000000: loss = 1.0283203125 (0.0 steps/sec)
INFO:Tensorflow:Evaluation [1/10]
INFO:Tensorflow:Evaluation [2/10]
:
INFO:Tensorflow:Evaluation [9/10]
INFO:Tensorflow:Evaluation [10/10]
INFO:root:Evaluation finished with 2560 samples in 4.58 seconds, 558.95 samples/second.
INFO:root:All control services terminated
INFO:Tensorflow:Saving dict for global step 1000000: global_step = 1000000, loss = 1.0734375
INFO:Tensorflow:Saving dict for global step 1000000: eval/accuracy_cls = 0.94570315, eval/accuracy_masked_lm = 0.78115207, eval/mlm_perplexity = 2.5195084
INFO:Tensorflow:Saving 'checkpoint_path' summary for global step 1000000: ./msl512/model.ckpt-1000000
INFO:Tensorflow:Host Call returns:eval/accuracy_cls: 0.9457031488418579
eval/accuracy_masked_lm: 0.781152069568634
eval/mlm_perplexity: 2.5195083618164062
そして今回のモデル作成の処理時間は、MSL128とMSL512それぞれで以下のような結果になりました。全体の処理時間は、約64.1時間=およそ3日足らずでモデル作成の処理を完了することができています。PUサーバーで数か月かかるようなケースと比較すると、驚異的な速さですね。
MSL512の学習モデル作成:53.3時間
合計 :64.1時間
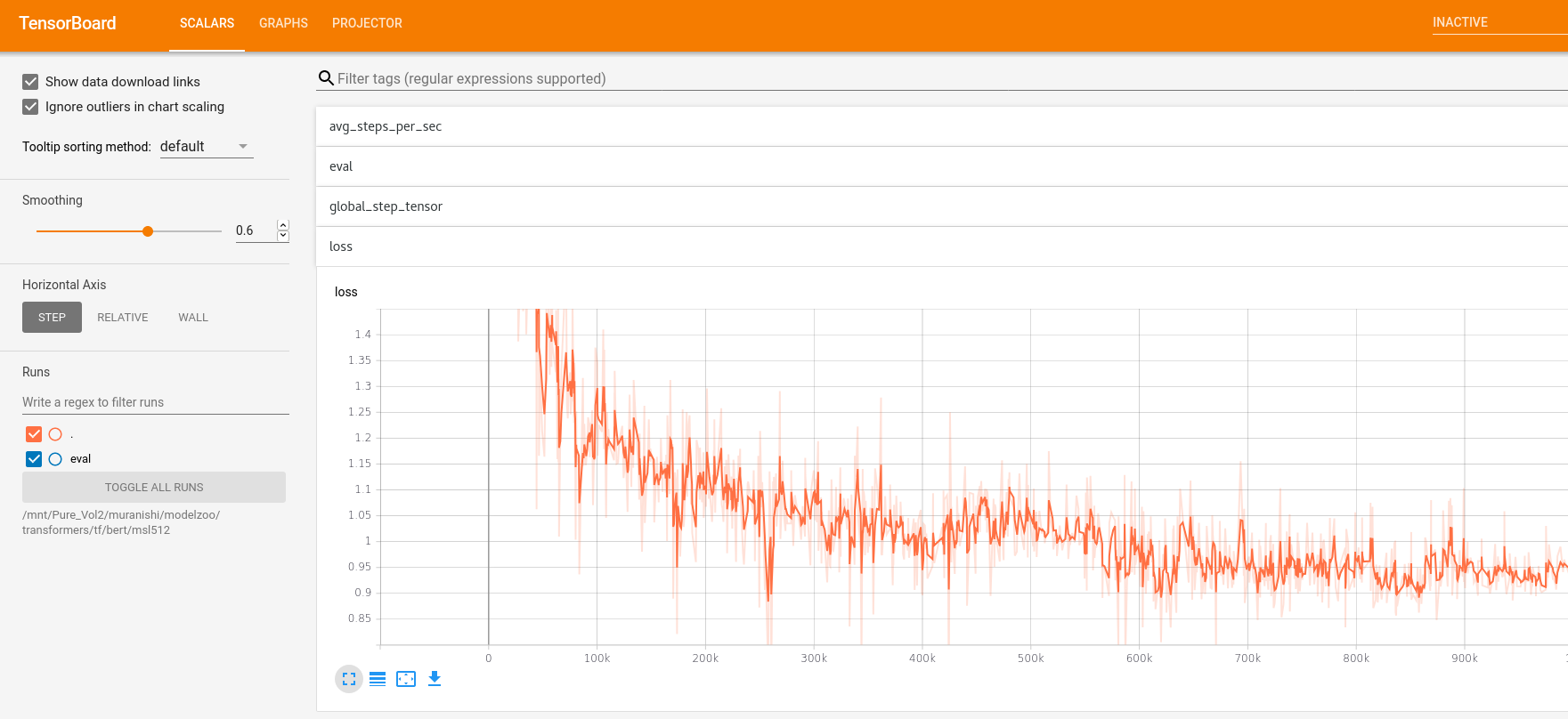
また、モデル作成の経過情報や結果は、Cerebras SinguralityコンテナにインストールされたTensorboardで学習途中の経過やモデル作成の結果を可視化することも可能です。
[Loss Graph]
[Embedding Projector(PCA)]
まとめ
Cerebras CS-2は通常のGPUと異なる構成が特徴的ですが、実際にモデル作成をしてみるとディープラーニングの標準的なpythonライブラリで処理できる仕組みを備えていることが分かります。かつ、処理時間が通常のGPUサーバーでは月単位でかかるところを、たったの3日間で高精度なモデルを作成することができました。
今回作成したBERT Largeの事前学習モデルは、利用タスクに合わせてファインチューニングを行うことで実際のサービス利用ができるようになります。今後は文書要約のファインチューニングを予定しています。
Cerebras CS-2の見学や説明会も随時承っています。ぜひお気軽にお問い合わせください!

この記事の投稿者AiM
AI関連の製品のサポートとプリセールスを担当しています
趣味はサイクリングとジョギング、でも最近はサボり気味です
この記事をシェア



