「TAIP エントリーモデル」を構築しました

この度、Dellテクノロジーズ社による協力のもと、弊社が提案している大規模AIモデル学習環境のリファレンス構成であるTED AI インフラパッケージ(TAIP) エントリーモデルの構築を行いました。今回はその内容について検証結果を交えてご紹介します。
TED AIインフラパッケージ(TAIP)とは
東京エレクトロンデバイスでは、NVIDIA製品やCerebras製品等、大規模なAIワークロードに適した演算装置を取り扱っています。AIアクセラレータと呼ばれるこれらの製品群に加え、ネットワークスイッチやフラッシュストレージといった一連のタスク処理に不可欠な周辺機器を厳選し、一元的なサポートの下、一つのパッケージとして提案するのがTED AI インフラパッケージ(TAIP)です。
TAIPは、オンプレミスでのゼロからの環境構築を可能にし、お客様の速やかなAI開発への着手と安定的な運用に貢献します。
TAIP エントリーモデル 構成
今回ご紹介するのは、Dell EMC PowerEdge R750xa + Dell EMC PowerScale F200、これらDellテクノロジーズ社製の機器を中心としたパッケージ、TAIPエントリーモデルです。
AIアクセラレータとしてNVIDIA A100 GPU、コンピュートとストレージを接続するためにArista社製のネットワークスイッチを採用しました。
この構成を特徴付けるアイデアと、裏付けのために今回行った検証内容を3点に分けてご紹介します。
アイデア1 一台でAIパイプライン (前処理・学習・推論)
本構成では、R750xaサーバーに搭載したNVIDIA A100 80GB GPUのMulti-Instance GPU (MIG) を活用することで、ディープラーニングに要求される各種処理、即ち
- データ前処理
- 学習
- 推論
の高速なパイプライン実行を可能にしています。
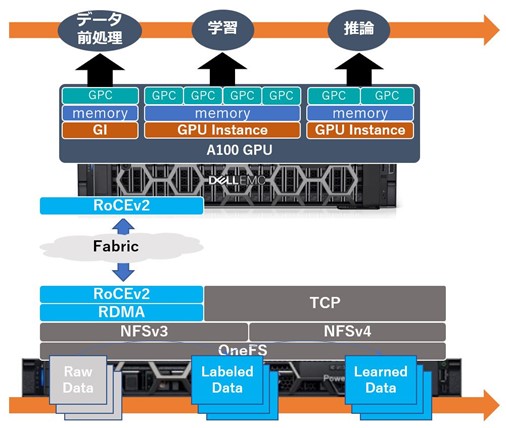
TAIP エントリーモデル構成 およびMIGの活用 概略
MIGは、GPUを最大7個のGPUインスタンス (GI) に分割する、NVIDIA製の一部ハイエンドGPUでサポートされている機能です。分割されたGIそれぞれに固有のメモリ、キャッシュ、演算コアを割り当てることで、一枚のGPUを用いて独立した複数のタスクを自由なリソース配分で実行させることを可能にしています。
今回の構成では、以下に図示したユースケースを想定しました。蓄積され続けるデータに対して、絶え間なくデータ前処理、学習、および推論を実行し続けられる環境を構築することを目指しています。
使用するAIモデルとして、画像セグメンテーションにおける代表的モデルであるU-Netを採用しました。今回のハードウェア構成では4つのGIを学習用、2つのGIを推論用に充てることでパイプライン実行に十分なリソースを確保できることが検証を通じて確認できました。
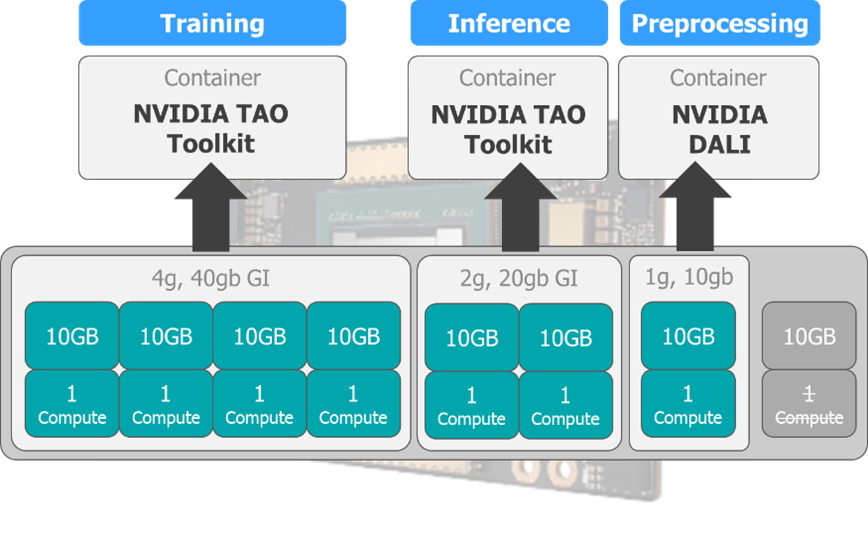
GPUインスタンス構成とタスクへの割り当て
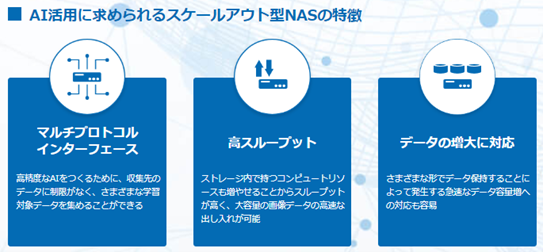
アイデア2 高性能ストレージをAIに活用
AI開発において、データの扱いは重要なファクターの一つを占めます。学習に用いるデータセットは勿論のこと、追加で収集されるデータや、それらを学習用に拡張(Data Augmentation)したデータ、AIモデルのチェックポイント等、開発が長期化するにつれてストレージ容量の要求も肥大化します。スループットとスケーラビリティの高い水準での両立が求められます。
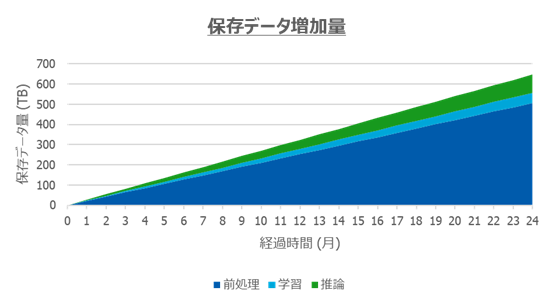
パイプライン処理による保存データ増加量のシミュレーション結果
今回採用したPowerScale F200はマルチプロトコルのスケールアウト型NASであり、スモールスタートでのデータストア構築と漸次的なスケーリングを実現する本製品は、エントリーモデルに必要な要素を万全に兼ね揃えていると言えます。

Dell EMC PowerScale F200
TAIPのようなシステムを構築する上での懸念事項の一つとして、データ保存領域の外部化によるアプリケーション処理性能の低下が考えられます。その影響の度合いを確認する方法として、今回はTAIPエントリーモデル構成とPowerEdge R750xaの内臓ディスクでのデータの読み書きを実施する構成(以下スタンドアローン構成)とでのパイプライン処理性能比較を実施し、その結果をテーブル1に纏めました。
| 評価項目 | バッチサイズ | TAIPエントリーモデル | スタンドアローン |
| 前処理A | 512 | 2.22M img/s | 3.20M img/s |
| 前処理B | 128 | 607K img/s | 716K img/s |
| 学習 | 16 | 27.9 img/s | 27.9 img/s |
| 推論 | 1 | 9.01 img/s | 9.18 img/s |
前処理AではNVIDIA DALIによる入力画像のローディング+デコード+ノイズ付加によるデータ拡張、
前処理BではNVIDIA DALIによる入力画像のローディング+デコード+画像回転によるデータ拡張処理を実施。
学習および推論という、一つのデータに対して複数回試行する必要のあるタスク≒実運用上ストレージアクセス頻度の高いタスクにおいては、ストレージを外部化することによる性能低下は殆ど見受けられませんでした。その一方で、各前処理タスクにおいては有意な性能低下が見られましたので、この点については今後改善を図りたいと考えています。
アイデア3 GPUをフル活用
AIワークロードにおける学習および推論タスクでのGPU利用は、個人・法人を問わず既に幅広く浸透しています。その一方で、画像ファイル等をテンソルとして読み込ませてモデル実行を可能にするまでの各種前処理(ローディング、デコード、データ拡張等)は、その大半がCPUに依存している実状があります。
本構成では、MIGによるGPU分割の効果を最大限に発揮させることを目的としてNVIDIA DALIを取り入れました。データ処理パイプラインのGPUオフロードを可能にするDALIによって、従来のAIワークロードにおけるCPUボトルネックを解消し、AI開発を更に加速させる効果が期待できます。
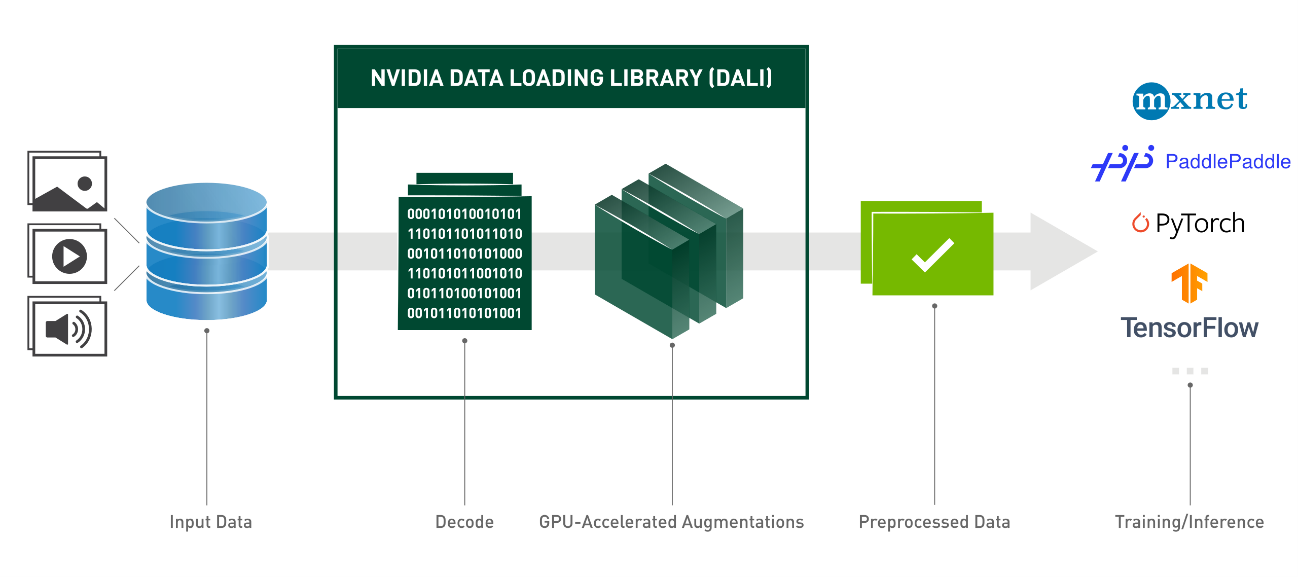
出典: https://docs.nvidia.com/deeplearning/dali/user-guide/docs/index.html
NVIDIA DALIは、NVIDIA社が提供するオープンソースのライブラリであり、PythonベースのAPIで簡単に利用することが可能です。今回の検証では、以下の図に示す二種類のデータ拡張をNVIDIA DALIで実行し、CPUとGPUでの前処理性能の比較を行いました。

NVIDIA DALIによるデータ拡張
上: 画像へのガウシアンノイズ付与
下: 画像とそのセグメンテーション用ラベルを回転処理
検証結果としては、当初の期待に反してCPUで実行した場合の方が処理性能が高いという結果が得られました。
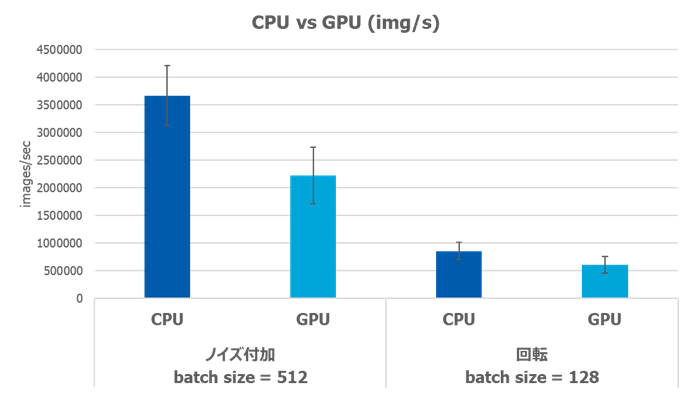
上記の原因として、GPUで前処理を行う際の画像データコピーによるオーバーヘッドが考えられます。
この図に示す通り、DALIによる前処理時にはCPUとGPUのどちらを使用する場合でも、ファイルは一旦メインメモリ(今回の場合はPowerEdge R750xaに搭載されているRAM)に読み込まれます。その後、GPUで処理する場合はjpgファイルからデコードされた画像データをA100 GPUのメモリにコピーする工程が生じます。同様に、データ拡張後の画像データをファイルとして保存する際にも、GPUメモリからメインメモリへコピーする必要があります。
データ拡張そのものの計算負荷が小さい程、前処理時間全体に占めるメモリ間コピーによるオーバーヘッドは支配的になります。性能比較を見るに、比較的演算コストの小さいノイズ付加と比較して回転処理での性能差は小さいため、今回の結果は前述の原因推定を支持しているようにも考えられます。
翻って、よりサイズの巨大な画像ファイルを処理させる、または更に演算コストの大きいデータ拡張手法を採用する等の場合は、メモリ間コピーによるロスを差し引いてもGPU上での前処理性能に軍配が上がる可能性は十分に考えられます。この辺りについては、様々なユースケースを通じて検証を深めていきたいと考えています。
最後に
TAIPエントリーモデルに限らず、東京エレクトロンデバイスはお客様への幅広いAIアクセラレータソリューションを提案しておりますので、今回の記事でご興味を持っていただけた方、AI活用に関する課題を抱えている方は、是非弊社までご連絡いただけましたら幸いです。


この記事の投稿者YM
この記事をシェア




