Cerebras LLM高速推論のAPIを試してみた

みなさん、こんにちは
CerebrasプリセールスエンジニアのNakadaです。
以前Cerebras社がサービスを開始したLLMの高速推論について紹介させて頂きましたが、今回はCerebrasが公開しているAPIアクセスで高速推論を実際に試してみました。
■環境設定:ユーザ登録とAPI Keyの作成
1.Cerebras APIを利用する前に
最初に以下のURLへアクセスし、ユーザ登録します。(無料)
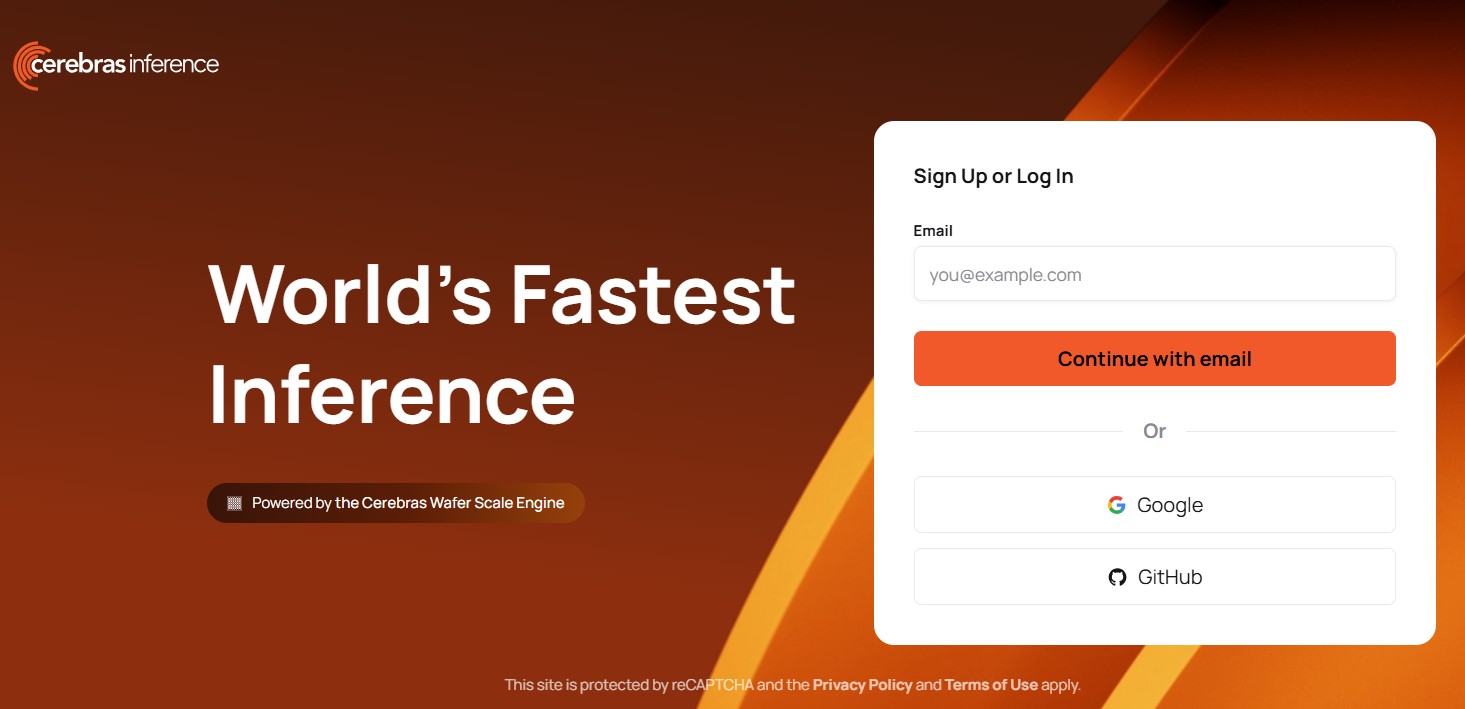
2.登録したユーザーでログインすると、以下の画面が開きます。
この画面では以下のLLMを使い、Playground上で文生成を試すことも可能です。
| Llama4 Scout |
| Llama3.1 8B |
| Llama3.3 70B |
| Deepseek R1 Distill Llama 70B |
| Qwen3 32B |
※最初の登録では、無料枠での利用となるためトークン生成のレート制限が掛かっています。有償版では制限が解除できますのでご興味がある方は当社までご連絡ください。
3.APIキーの作成
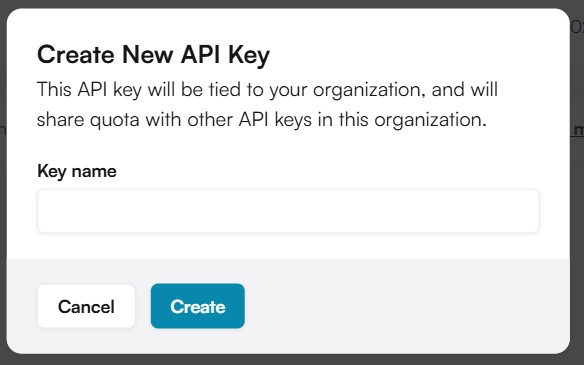
画面左の「API Keys」を開き、「Generate API Key」ボタンを押します。
「Create New API Key」ウィンドウが開きますので、任意のKey nameを入力してください。入力後に「Create」を押すとAPI Keyが生成されます。
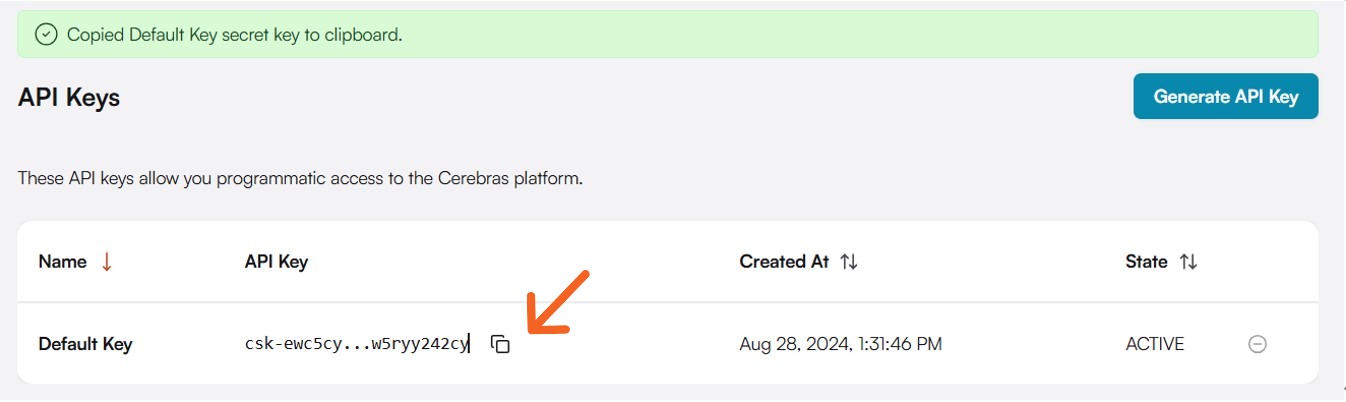
API Keyが生成されるとAPI Keys画面に作成したAPI Keyが表示されます。
ここで作成したAPI Keyはこのあとの設定で利用します。
■環境設定:Cerebras API SDKのインストール
1.インストール環境要件
Python 3.7以上もしくはTypeScript 4.5以上がインストールされていること
2.Cerebras API SDKのインストール
「pip install cerebras_cloud_sdk」を実行します。
3.環境変数を設定する
export CEREBRAS_API_KEY=”your-api-key-here”
「your-api-key-here」には「環境設定:ユーザ登録とAPI Keyの作成」で作成したAPI Keyを指定してください。API Key画面よりコピーできます。
■実際に利用してみる
以下のようなPythonコードを作成します。
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
api_key=os.environ.get(“CEREBRAS_API_KEY”),
chat_completion = client.chat.completions.create(
messages=[
{
“role”: “user”,
“content”: “なぜ、高速な推論は必要なのですか?”,
}
],
model=” llama-4-scout-17b-16e-instruct “,
)
print(chat_completion)
上記コードですが、利用するLLMは「llama-4-scout-17b」を指定し、LLMへの質問は「なぜ、高速な推論は必要なのですか?」としています。また、エンドポイントフォーマットは「chat completion」を指定しています。
なお、無償版で指定できるLLMは以下です。
| モデル名 | コード内で利用する識別名 |
| Llama 4 Scout | llama-4-scout-17b-16e-instruct |
| Llama 3.1 8B | llama3.1-8b |
| Llama 3.3 70B | llama-3.3-70b |
| Qwen 3 32B | qwen-3-32b |
| DeepSeek R1 Distill Llama 70B | deepseek-r1-distill-llama-70b |
では、実行してみましょう。以下のように生成されました。
ChatCompletionResponse(id=’chatcmpl-93358162-6424-4f0f-a3b6-b2807c01caa5′, choices=[ChatCompletionResponseChoice(finish_reason=’stop’, index=0, message=ChatCompletionResponseChoiceMessage
(role=’assistant’, content=’推論の高速化は、多くの人工知能 (AI) アプリケーションの重要な側面です。推論とは、トレーニング済みの機械学習モデルを使用して予測や意思決定を行うプロセスです。推論を高速化する必要性は、いくつかの要因によって生まれます。\n\n1. **リアルタイム処理**: 多くの AI アプリケーションは、リアルタイム処理を必要とします。たとえば、自動運転車は、安全性と有効性を確保するために、非常に短い時間内に予測と決定を行う必要があります。推論が速いほど、車は環境の変化に迅速に対応できます。\n\n2. **スケーラビリティ**: AI モデルの使用が拡大するにつれて、多数のユーザーをサポートし、大量のデータを迅速に処理する必要があります。推論の高速化により、リソースの効率的な使用が可能になり、多数の同時リクエストを処理できるようになります。\n\n3. **エネルギー効率**: 推論の高速化は、特にモバイル デバイス や組み込みシステムなどのエネルギー制限のある環境では、エネルギー効率に直接影響します。推論が高速かつ効率的に実行されると、消費電力が削減され 、バッテリー駆動デバイスの寿命が延びます。\n\n4. **ユーザーエクスペリエンス**: 迅速な推論により、応答時間が短縮され、ユーザーエクスペリエンスが向上します。検索エンジン、推奨システム、チャットボットなどのアプリケーションでは、パフォーマンスが優れているとユーザーの満足度が高まり、離脱率が低下します。\n\n5. **コスト削減**: 高速な推論により、データセンターの運用コストを削減できる場合があります。推論を高速化すると、サーバーの負荷が軽減され、レイテンシが短縮されるため、必要なハードウェアリソースとエネルギーが少なくて済みます。\n\n6. **エッジコンピューティング**: クラウドからネットワークのエッジへの AI推論の移行が進むにつれて、高速な推論がさらに重要になっています。エッジデバイスは多くの場合、限られた処理能力と電力しかないため、効率的で高速な推論アルゴリズムが不可欠です。\n\n7. **競合他社との差別化**: 市場の多くの分野で、高速な推論機能は競争上の優位性につながります。競合他社が類似の AI を活用した製品を提供している場合、迅速な応答とスムーズなユーザーエクスペリエンスを提供する製品が選ばれる可能性が高くなります。\n\nこれらの要因を達成するには、ハードウェアの加速 (GPU、TPU、FPGA など)、モデル最適化 (量子化、プルーニ ング、知識の蒸留など)、効率的なソフトウェア フレームワークなど、推論の高速化に使用されるさまざまな技術があります。これらの技術を組み合わせる ことで、AI システムが迅速かつ効率的で効果的な推論を実行できるようになり、幅広いアプリケーションやユースケースで AI の採用がさらに促進されます。’
tool_calls=None), logprobs=None)],
created=1752209674, model=’llama-4-scout-17b-16e-instruct’, object=’chat.completion’, system_fingerprint=’fp_557bfe2a5b5c504cad63′,
time_info=ChatCompletionResponseTimeInfo(completion_time=0.673703249
prompt_time=0.000992401
queue_time=0.00010644
total_time=0.6769323348999023
created=1752209674),
usage=ChatCompletionResponseUsage(completion_tokens=644
prompt_tokens=21, prompt_tokens_details=ChatCompletionResponseUsagePromptTokensDetails(cached_tokens=0)
total_tokens=665)
service_tier=None)
一瞬で生成されました。
生成された内容については、Llama4 Scoutだけあって違和感のない流暢な日本語文が生成されていることが分かります。
今回注目して頂きたいのは、生成のスピードです。生成文の後に、以下のような生成スピードの情報が記録されています。
|
Prompt_tokens=21 |
入力トークン数 |
|
completion_tokens=644 |
出力トークン数 |
|
completion_time=0.673703249 |
生成時間(秒) |
|
total_time=0.6769323348999023 |
生成が完了するまでの時間(秒) |
|
Total_Tokens=665 |
入出力の全トークン数 |
結果として644トークンをたった、「0.67秒」で生成しています。
如何でしょうか。ユーザ登録からAPI Key生成、Cerebras API SDKのインスール、簡易コードを作成まで簡単に準備できるにもかかわらず、他のLLM APIサービスと比較しても圧倒的に高速なLLMアクセスを利用できました。
■おまけ
簡易生成ツールのコードを用意しました。質問を入力すると回答と生成時間が表示されます。Exitを入力すると終了します。
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
api_key=os.environ.get(“CEREBRAS_API_KEY”),
)
while True:
user_input = input(“入力してください(終了するには ‘Exit’ と入力):”)
if user_input.lower() == “exit”:
print(“終了します。”)
break
chat_completion = client.chat.completions.create(
messages=[
{
“role”: “user”,
“content”: user_input,
}
],
model=”llama-4-scout-17b-16e-instruct”,
)
# content部分だけを抽出して表示
try:
content = chat_completion.choices[0].message.content
completion_time = chat_completion.time_info.completion_time
print(“回答:\n\n” + content + “\n”)
print(f”生成時間: {completion_time:.3f} 秒”)
except Exception as e:
print(“情報の抽出に失敗しました:”, e)
■最後に
Cerebras API SDKを使って、高性能なオープンソースLLMを高速に利用できるCerebras APIサービスを試してみました。如何でしたでしょうか。
APIアクセスとなりますので、Cerebrasの高速推論システムを様々なアプリケーションと連携させることもできます。今回は簡易的なコードで試してみましたが、次回はアプリケーションと連携して試したいと思っています。最後に、このブログをお読みになり、LLM及びAIアクセラレータ製品、高速推論等にご興味がある方は当社までお問合せ頂ければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア


