LangChain AgentでCerebras高速推論を使ってみた

みなさん、こんにちは
CerebrasプリセールスエンジニアのNakadaです。
前回Cerebras社のLLM高速推論APIアクセスサービスを試しましたが、今回は実際の生成AIの活用ということで、LangChainと連携してLLM自身で最新のニュース情報を検索してくれるAIエージェントを試してみました。
■デモの概要
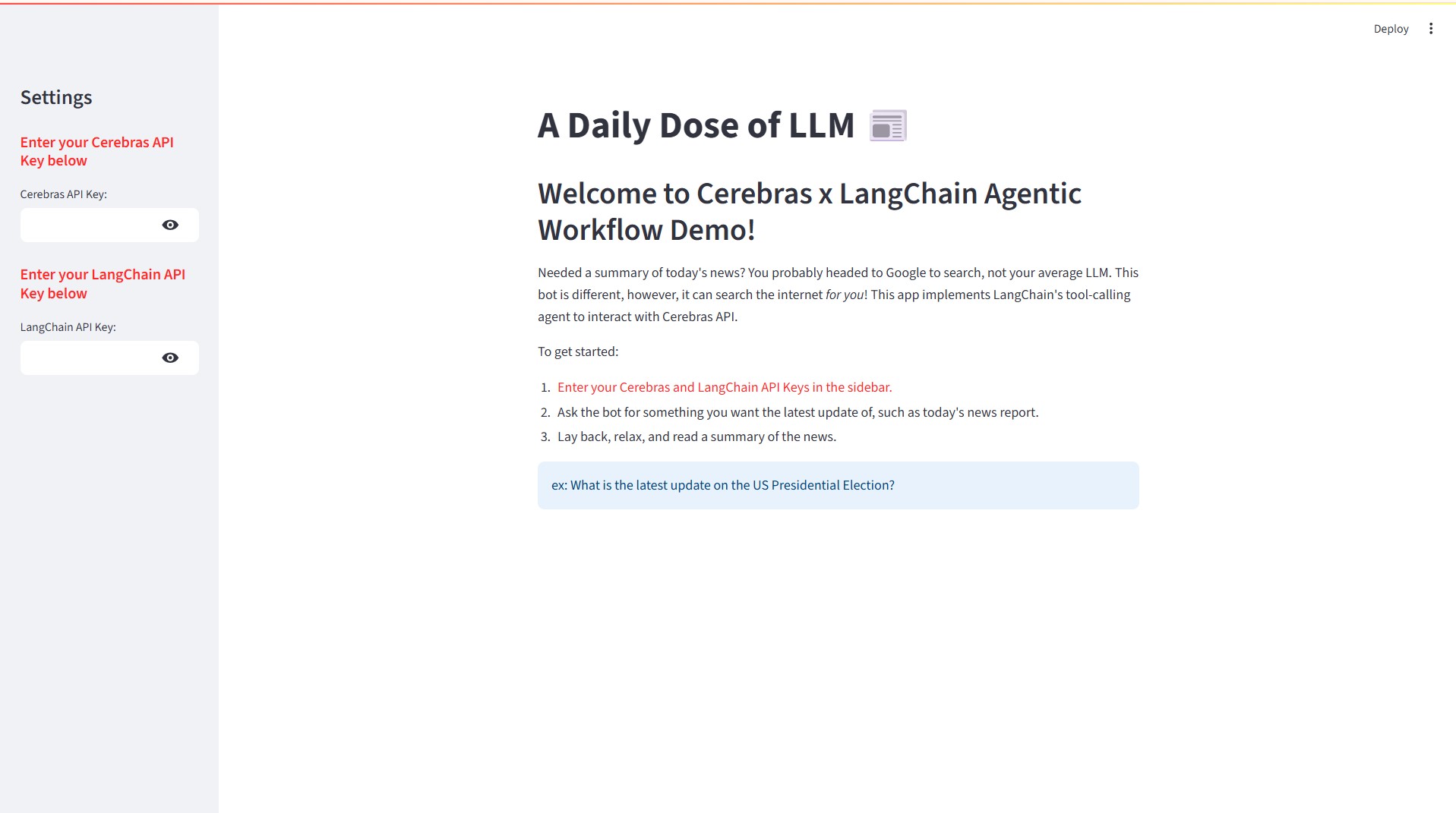
今回のデモはLangChainのAgent機能を使います。Web検索はAgent機能がサポートしているDuckDuckGo検索エンジン(ddg-search)とwikipedia検索エンジンを利用します。LLMはCerebrasの高速推論APIと連携し、llama-4-scoutを利用します。利用するコードはCerebras社が用意したデモコードを使い、LangChainのStreamlitでGUI環境を作成します。GUIの画面イメージは以下になります。
■CerebrasとLangChainのAPIキーを作成する
1.Cerebras APIキーを作成する
最初に以下のURLへアクセスし、ユーザー登録します。(無償)
 Cerebras APIキーの作成についてはこちらの記事を参照してください。
Cerebras APIキーの作成についてはこちらの記事を参照してください。
2.LangChain(LangSmith)のAPIキーを作成する
こちらからアクセスしてユーザーアカウントを登録後に画面左の設定ボタン(赤枠)よりAPIキーを作成してください。以下のCreate API Keyボタン(赤枠)からAPIキーが作成できます。以下は「Create API Key」の設定画面です。Descriptionに任意の名前を入力して、Create API Keyボタンを押すとAPIキーが作成されます。Key TypeとExpiration Dateも任意の設定が可能です。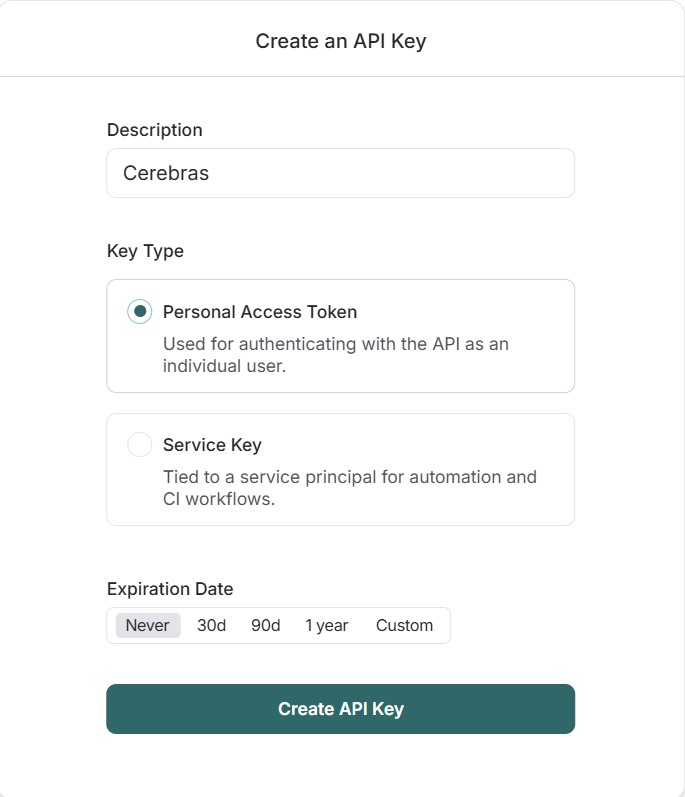
■環境設定
1.インストール環境要件
Python 3.7以上がインストールされていること
※Dockerなどの仮想環境でもOKです。
2.コードのダウンロード
「git clone https://github.com/Cerebras/inference-examples.git」を実行します。
3.ai-workflow-langchainディレクトリに移動し、必要なアプリケーションをインストール
cd inference-examples/ai-workflow-langchain/
pip install -r requirements.txt
4.main.pyを編集して、Llama4 ScoutモデルをLLMに設定する。※llama-3.3-70bを利用する場合はこの設定は必要ありません。
vi main.pyを実行し、「llm = ChatCerebras(model=”llama-3.3-70b”, api_key=api_key)」の行を
「llm = ChatCerebras(model=” llama-4-scout-17b-16e-instruct “, api_key=api_key)」へ変更します。
5.Streamlitの実行
「streamlit run main.py」
以下のようにエラーなく、以下のメッセージが出力されれば正常に起動しています。
■実際に利用してみる
上記の手順によりStreamlitが起動すれば、ブラウザから以下の画面にアクセスできます。Streamlitを起動したホストからブラウザを開く場合は「http://localhost:8501」でアクセスできます。
1.画面が開いたら、画面左にCerebrasのAPIキーとLangChainのAPIキーを入力する場所がありますので、事前に登録したAPIキーを入力してください。
2.APIキーを入力すると、右の画面が入力画面に代わります。
3.何か質問を入力し、「Generate output」を押してみましょう。
例として「2025年の重要ニュースを解説と一緒に説明してください。」と入力し、「Generate output」を押してみました。Generating result…と表示され、以下が出力されました。
「Verbose Output(Step by Step)」は、最後に生成される回答にたどり着くまでの検索結果をステップバイステップで表示します。最新のLLMで話題になっているChain of Thoughtのように段階的に検索結果をLLMが判断し結果を表示します。生成の最後には以下のような回答が生成されました。
| Your result:
2025年の重要ニュースとしては、以下のようなものが挙げられます。
また、2025年には以下のようなニュースも報道されています。
ただし、2025年は未来の年であり、現在の情報では正確な情報を提供することができません。最新のニュースや出来事については、随時更新される情報を参照する必要があります。 |
内容は、大阪万博や参議院選挙について生成されており、日付も正しい内容で生成されていることが分かります。
■生成された内容を分析してみる
今回、LangChain(LangSmith)とAPIで連携しましたが、これにより生成内容の分析も可能です。LangChainのAPIキーを作成したサイトから以下のTracing Projectsを確認してみます。Tracing Projectsにdefaultという名前のProjectがあるので、クリックすると以下のようにCerebras高速推論のLLMで生成された内容が記録されています。
更に記録されたレコードをクリックする検索した内容や処理に掛かった時間などの情報も確認することができます。表示された内容の左側のウィンドウには、ステップバイステップで処理された内容が順番に記録されています。以下は「ChatCerebras」がLLMの処理、「duckduckgo_search」と「wikipedia」がWeb検索の処理となります。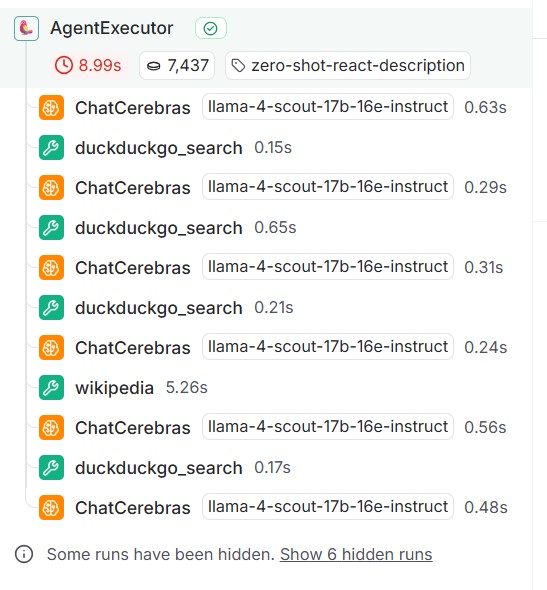 結果はWaterfall形式で処理時間を見ることに可能ですが、LLMの処理(ChatCerebras)がすべて1秒以内で完了していることが分かります。これがCerebras高速推論の恩恵になります。
結果はWaterfall形式で処理時間を見ることに可能ですが、LLMの処理(ChatCerebras)がすべて1秒以内で完了していることが分かります。これがCerebras高速推論の恩恵になります。
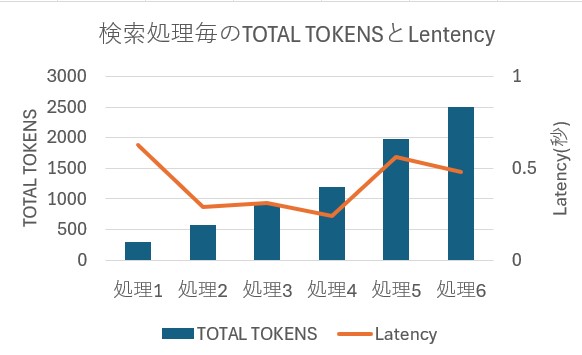
今回のデモでは、LangChainのAgent機能を使い、Chain of Thoughtのように検索結果を元にLLMが回答を生成していますが、上記の図のように繰り返し処理が続くことでLLMに入力されるトークンも増加していきます。LangChainのTracing Projectsでは、以下のように生成時間などと一緒にLLMで入出力したトークン数(TOTAL TOKENS)も記録されます。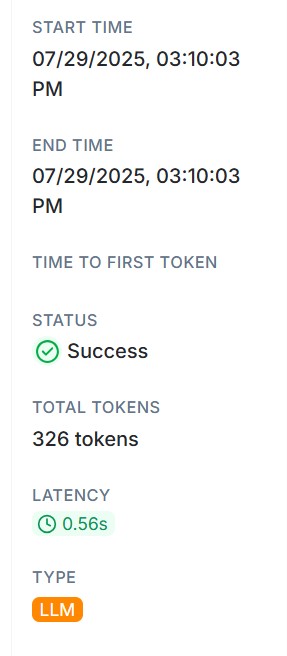 検索処理毎のトークン数をプロットすると以下のグラフになります。TOTALTOKENSは処理毎に増加し、最後は2500トークンを処理していますが、LLMレイテンシは全て1秒以内で処理していることが分かります。
検索処理毎のトークン数をプロットすると以下のグラフになります。TOTALTOKENSは処理毎に増加し、最後は2500トークンを処理していますが、LLMレイテンシは全て1秒以内で処理していることが分かります。
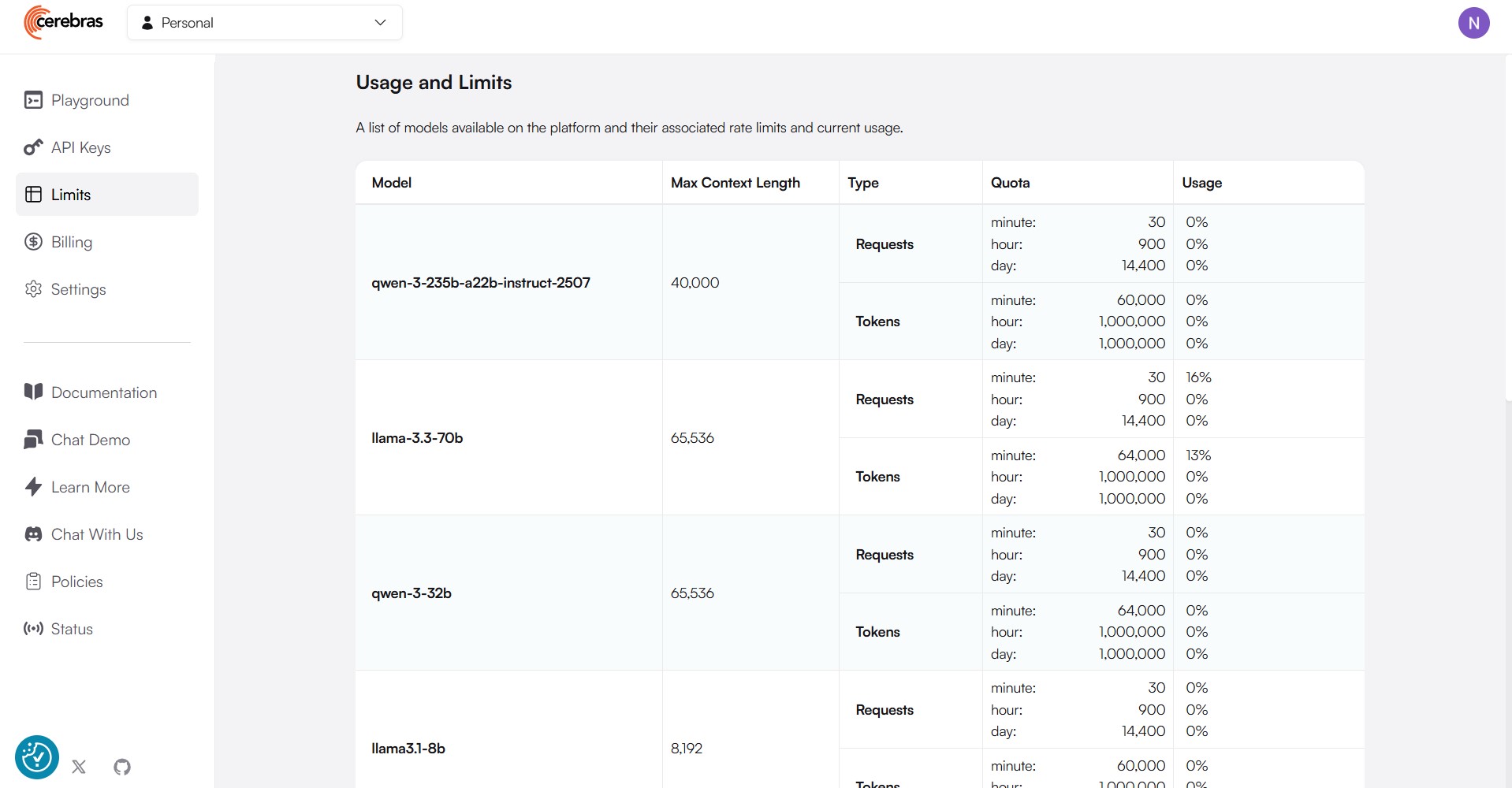
Cerebras API Keyを登録したサイトから高速推論の利用状況も確認できます。Cerebras APIキーを作成したhttps://cloud.cerebras.ai/にアクセスし「Usege and Limits」を確認することで選択したLLMの利用状況を確認できます。
今回のデモはCerebras高速推論の無料枠内で実行しているため、コンテキストウィンドウサイズの制限はLLMへのリクエスト数の制限が掛かりますのでご注意ください。なお、有償版では制限が解除されますので、本格的に利用したいなどご要望があれば当社にお問い合わせください。
■最後に
今回は、Cerebras高速推論サービスをLangChainのAgentと連携してみました。最近の最新LLMはモデルサイズの巨大化は当然のことながら、Chain of Thoughtを実装したり、コンテキストウィンドウサイズが1000万トークンをサポートしたりと、より大きくのトークンを処理する必要があります。Cerebrasの高速推論はCerebras社の巨大チップ(21.5cm角)を利用したAIアクセラレータを使うことで、一般的なGPUを凌駕するLLM推論性能を実現しています。一度、今回のデモをご利用いただき、高速推論のメリットを実感頂ければと思います。最後に、このブログをお読みになり、LLM及びAIアクセラレータ製品、高速推論等にご興味がある方は当社までお問合せ頂ければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア



{kind=link}
{kind=link}