Cerebras LLM高速推論サービスアップデート情報

みなさん、こんにちは。CerebrasプリセールスエンジニアのNakadaです。
以前、Cerebras社がサービスを開始したLLMの高速推論について紹介させていただきましたが、今回はアップデート情報ということで最新情報をお知らせします。
■OpenAIとの提携
Cerebras社はOpenAI社との提携を発表しました。LLMの応答を大幅に高速化することを目的として、2028年までに複数の段階に分けてCerebrasのAIアクセラレータを提供するそうです。これにより、難しい質問やコード生成、画像生成、AI エージェントを実行する際に繰り返し行われるLLMの思考や何らかの応答の処理をリアルタイムで応答できるようになります。このリアルタイム応答により、ユーザーはストレスなく、AIを使うことができるようになります。
導入の規模としては、750MWの計算能力となるCerebrasの超低遅延AIシステムをOpenAIのプラットフォームに導入するそうで、750MWはだいたい石油火力発電1基分くらいの電力量になるようです。数十万世帯を賄えるくらいの電力量となるので、かなりの大規模なシステムになりそうです。
■Cerebras推論データセンター

Cerebras社はAIアクセラレータであるCS-3をベースに推論用システムを自社のデータセンターに構築して推論サービスを展開しています。写真はオクラホマ州のオクラホマシティに構築したデータセンターの写真です。アメリカおよびカナダ、ヨーロッパで8か所のデータセンターを構築しています。更には南米のガイアナに100MW級のデータセンターの構築を予定しているそうです。ヨーロッパではMistral AI社が対話型AI「Le Chat」のLLM基盤としてCerebras CS-3を利用しているため、その流れでデータセンターを構築したのだと思います。
【Cerebrasデータセンター 2026年2月現在】
| カリフォルニア州サンタクララ |
| カリフォルニア州ストックトン |
| ダラス、テキサス州 |
| ミネアポリス、ミネソタ州 |
| オクラホマシティ、オクラホマ州 |
| カナダ、モントリオール |
| 米国中西部/東部(2025年第4四半期) |
| ヨーロッパ(2025年第4四半期) |
■なぜ大規模自然言語モデル(LLM)の推論は遅いのか
OpenAI社はLLM推論を高速に処理できるハードウェアとしてCerebrasを選びましたが、なぜ、LLMの推論は遅いのでしょうか。
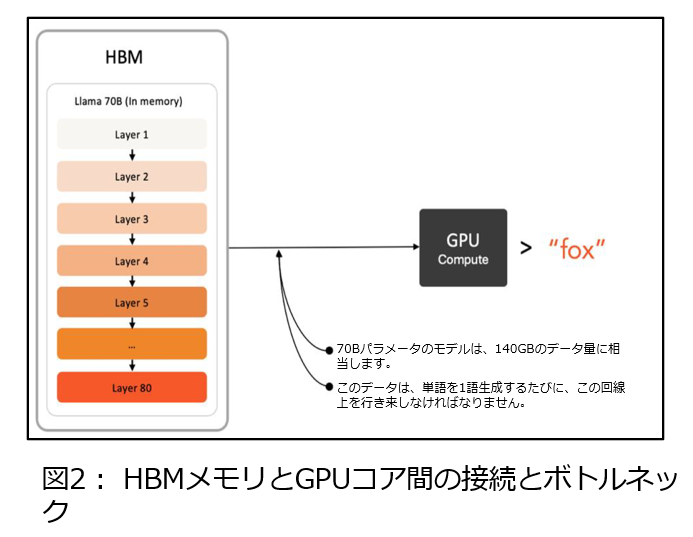
それは昨今のLLMは高精度に回答できますが、コンテキストサイズの拡大やChain of Thoughtなどの導入により推論処理が遅くなっています。LLMは1トークンを生成するたびにLLMの全レイヤーを通過し(図1)、それをEOSトークンが出るまで繰り返すため、1000トークンなら全レイヤーを1000回通過します。この処理を高速化するにはGPUの計算能力に加え、レイヤー情報やKVキャッシュを格納するメモリへのアクセス速度が重要であり、推論速度低下の主因はこのメモリアクセスのボトルネックです(図2)。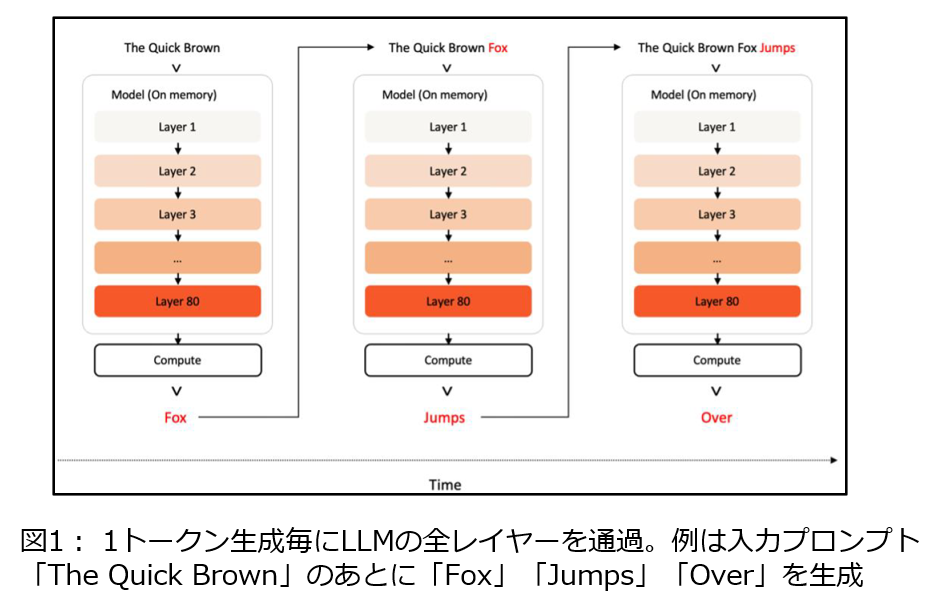
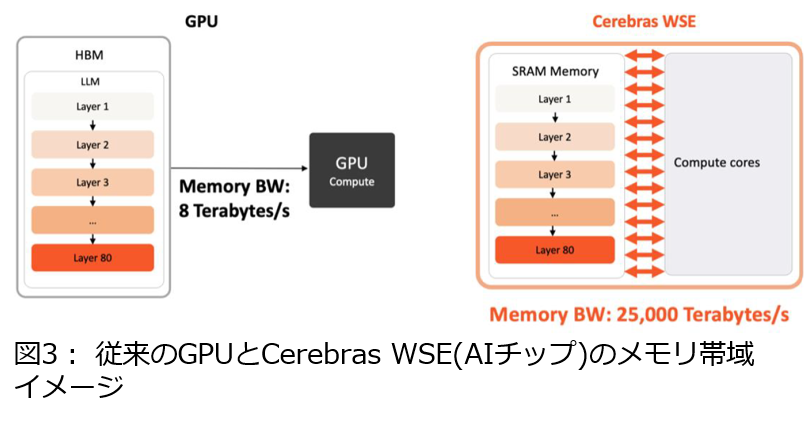
 このメモリアクセスのボトルネックを解消するにはGPUのハードウェア制限の克服が必要となります。Cerebras社が開発したCS-3は大量の演算コアとメモリを1チップに集約することで、21PB/secの超高速メモリアクセスを実現してメモリボトルネックを解消します(図3)。このCS-3を用いたクラウドサービスが「Cerebras高速推論サービス」となっていて、OpenAI gpt-oss-120bなど著名なオープンソースLLMを従来GPUより数十倍高速に実行でき、提供するSDKのAPIで簡単に利用できます。今後更に巨大化していくLLM/Agentic AI時代に最適なLLM推論環境として利用可能だと思います。
このメモリアクセスのボトルネックを解消するにはGPUのハードウェア制限の克服が必要となります。Cerebras社が開発したCS-3は大量の演算コアとメモリを1チップに集約することで、21PB/secの超高速メモリアクセスを実現してメモリボトルネックを解消します(図3)。このCS-3を用いたクラウドサービスが「Cerebras高速推論サービス」となっていて、OpenAI gpt-oss-120bなど著名なオープンソースLLMを従来GPUより数十倍高速に実行でき、提供するSDKのAPIで簡単に利用できます。今後更に巨大化していくLLM/Agentic AI時代に最適なLLM推論環境として利用可能だと思います。
■最後に
今回はCerebrasの高速推論サービスアップデートとして、OpenAIとの提携や現在のCerebras、そして、LLMの推論がなぜ遅いのかを簡単に説明させていただきました。次回は最近のAI評価でDifyを使ったついでにCerebrasの高速推論APIも実装したので、Difyへの実装方法やDifyで作成したチャットボットで体感としてどのくらい速いのかをブログで紹介したいと思います。
最後に、このブログをお読みになり、LLMおよびAIアクセラレータ製品、高速推論等にご興味がある方は当社までお問い合わせいただければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア

