NGINX Plusはアクティブヘルスチェックが使える!

NGINX PlusではOSS版では利用できないアクティブヘルスチェックがご利用いただけます。今回はアクティブヘルスチェックの設定方法を紹介します。
サーバーの死活監視
BIG-IPなどのロードバランサをご利用の方は、既にご存じの方も多いかと思いますが、サーバーの死活監視の方法にアクティブヘルスチェックというものがあります。
OSS版のNGINXではパッシブヘルスチェックしか使えず、アクティブヘルスチェックは使えませんが、商用版のNGINX Plusではどちらも利用することが可能です。
OSS、Plusの違い
NGINX OSSではパッシブヘルスチェックを使用することができますが、アクティブヘルスチェックを使用することができません。
NGINX Plusではパッシブヘルスチェック、アクティブヘルスチェック共に使用することができます。
| 方式 | NGINX OSS | NGINX Plus |
|---|---|---|
| パッシブヘルスチェック | ○ | ○ |
| アクティブヘルスチェック | × | ○ |
ヘルスチェック方式の違い
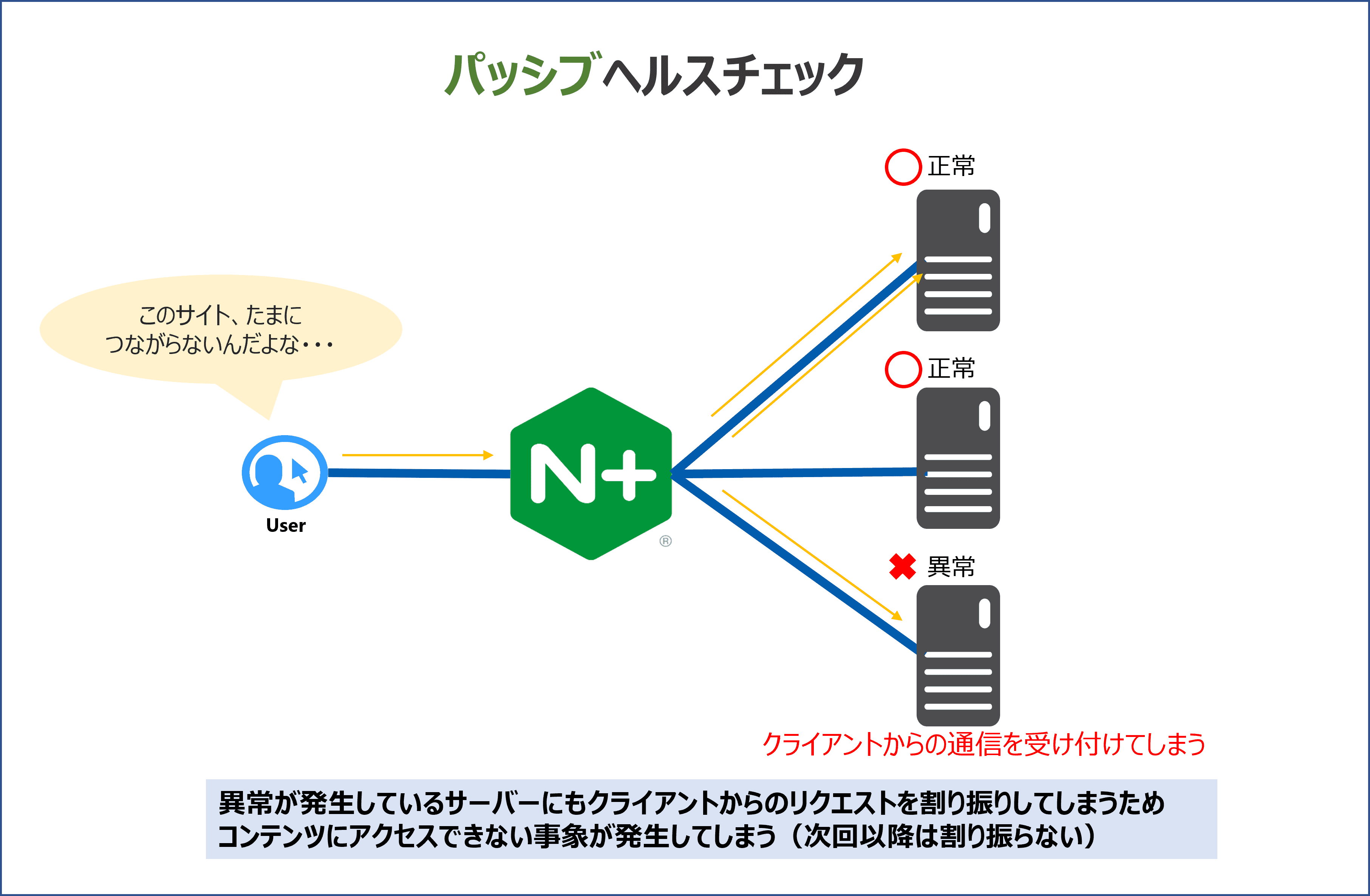
パッシブヘルスチェックは、読んで字のごとく受け身なヘルスチェック手法です。
クライアントからのリクエストに対するサーバーからの応答をチェックすることによって、死活監視をしています。
クライアントからのリクエストを用いてサーバーの死活監視をすることになるので、実際の通信が発生するまでサーバーのダウンを検知することができません。
サーバーのエラーを検知してからは、ダウンしているサーバーを割り振るグループから除外して他のサーバー群にのみ、リクエストを割り振るようになります。
しかし、パッシブヘルスチェックは一定の時間(fail_timeoutの設定値)が経過するとダウン状態を解除してしまうためクライアントからの通信がダウンしているサーバーに何度もリクエストを割り振ってしまいます。
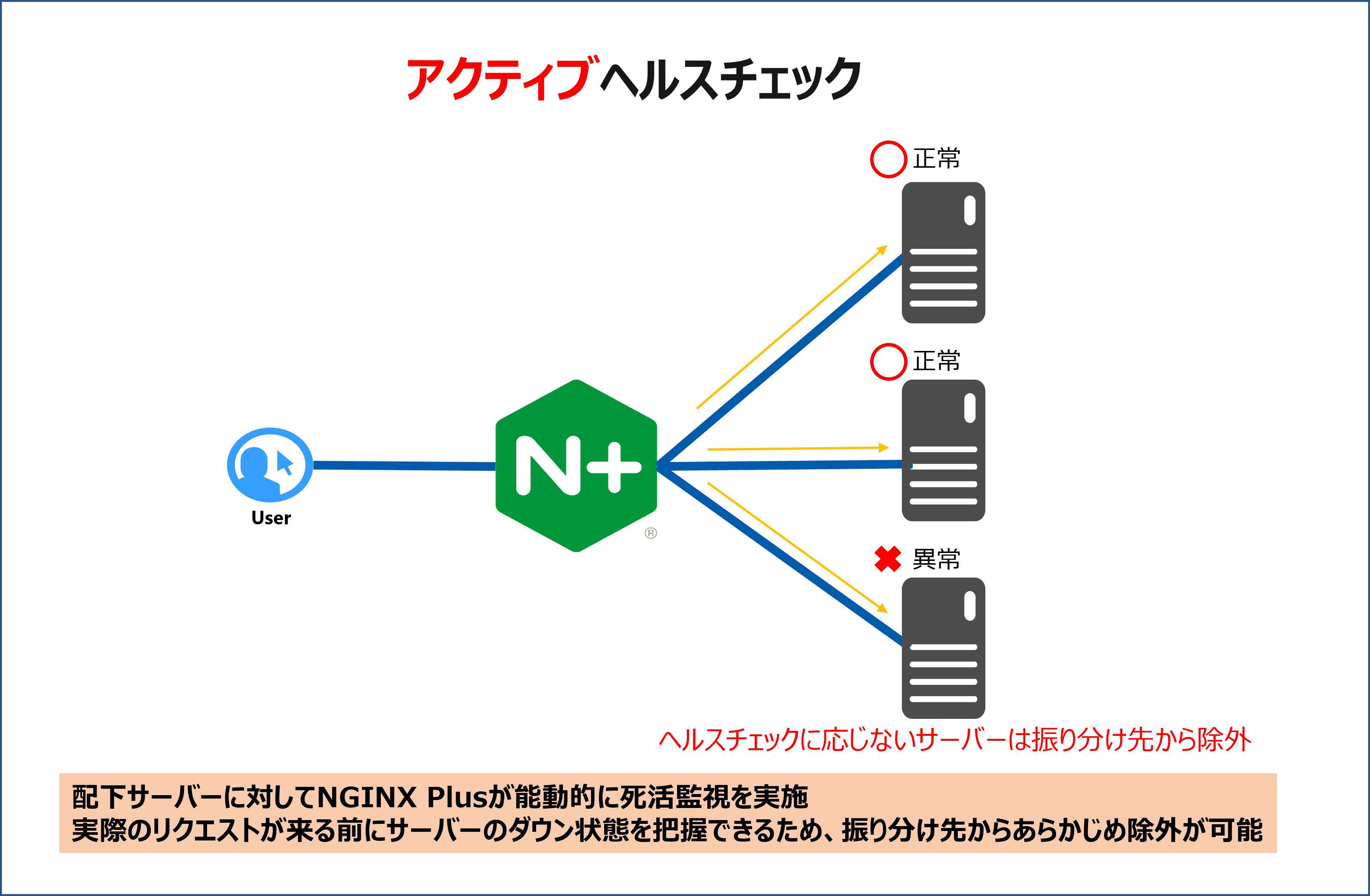
それに対し、アクティブヘルスチェックはNGINX Plus(ロードバランサ)自身が動的にヘルスチェックを行うためクライアントの通信前にサーバーの障害を検知することができます。
※アクティブヘルスチェックの場合でもヘルスチェックを送信する間隔(interval)とクライアント通信のタイミング次第では、サーバーエラー検知前にクライアント通信がエラーとなることもございます。
また、アクティブヘルスチェックではサーバーダウン後もヘルスチェックを定期的に送信しますので、サーバー復旧後にヘルスチェックに成功した場合、ダウンしていたサーバーは分散先に戻ることができます。
以下の画像がパッシブヘルスチェックとアクティブヘルスチェックのイメージになります。
設定方法
NGINX Plusのアクティブヘルスチェックの設定方法を紹介します。
設定としては以下のように、health_check;をlocationブロック内に記述するだけです。
デフォルトではサーバーに対して5秒間隔でリクエストを送信して死活監視をしています。
server {
location / {
proxy_pass http://backend;
health_check;
}
}また、オプション設定も多く存在していますので代表的なものを紹介します。
| オプション | 説明 |
|---|---|
| port | リクエストのやり取りをするポート番号の指定 |
| interval | ヘルスチェックのリクエストを送る間隔 |
| fails | 連続で何回リクエストに失敗したら異常とみなすかの回数 |
| passes | 連続で何回リクエストに成功したら正常とみなすかの回数 |
| uri | ヘルスチェックで使用するURIの指定 |
上記のように様々な値の指定ができますので要件に合わせてチューニングすることが可能です。
その他のオプションなどはこちらのURLに詳しく記載がありますので併せてご確認ください。
設定例などはこちらに詳しく載っておりますので、こちらも参考にしていただければと思います。
さいごに
NGINXをご利用中のお客様の中にはアクティブヘルスチェックを導入したことで、エンドユーザー様からのWebページが見られないことが多い!といったクレームが減少したというお話もございます。
NGINXをご利用中の方はNGINX Plusでしか使えない拡張機能に目を向けてみるのも良いのではないでしょうか。
今後、他の拡張機能なども紹介していきますのでお楽しみに!

この記事の投稿者Jo Nishikawa
セキュリティ製品のプリセールスを担当しています!
この記事をシェア