NIM(NVIDIA Inference Microservices)を使ってみましたPart2

みなさん、こんにちは
CerebrasプリセールスエンジニアのNakadaです。
前回、「NIM(NVIDIA Inferenece Microservices)を使ってみました」にてNVIDIA Inference Microservices for LLM(以下NIM for LLM)のレポートを掲載させていただきました。今回は前回NIM for LLMで起動させたmeta/llama3-8b-instructを更にNIMを使ってUI環境まで構築しましたので、そのレポートを掲載します。
■NVIDIA Inference Microservices for LLMのUI環境
NIMはNVIDIAが提供するAI モデルを本番環境にデプロイするためのマイクロサービスですが、UI環境に必要な機能をNIMコンテナとして準備されているので、これを使うことで、AI モデルのデプロイが簡素化かつ効率的に行えるようになります。今回はLLM環境となりますが、必要な機能として以下が準備されています。
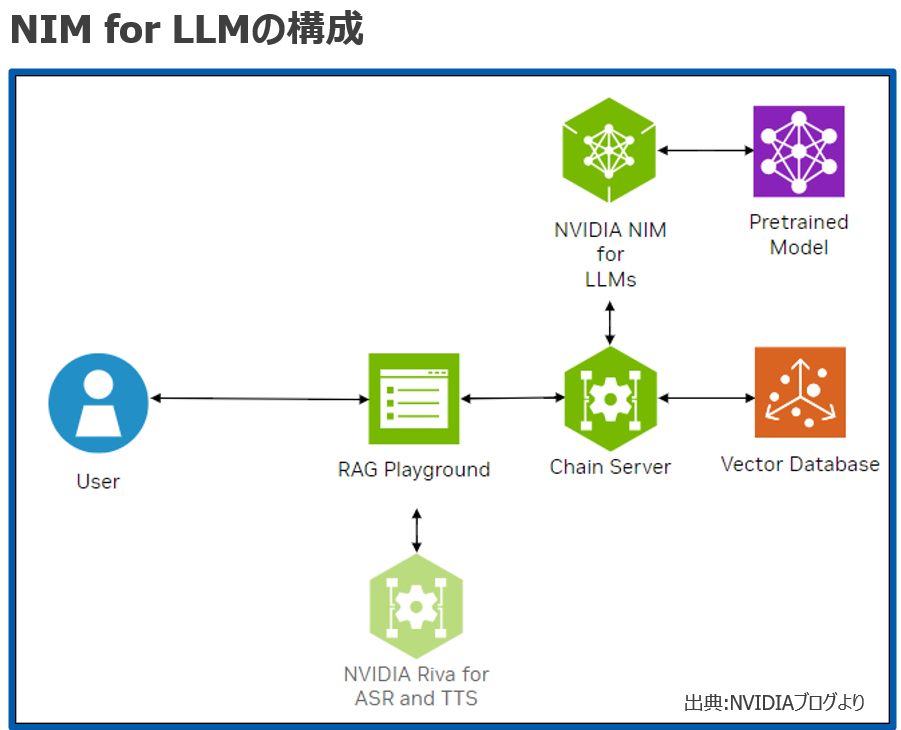
| RAG Playground | ユーザがアクセスするためのChatbotインターフェース |
| Chain Server | RAGサーバーとエンベッディングサーバー |
| Vector Database | PDFなどのドキュメントを元にベクトル化されたデータを保存するデータベース |
| NVIDIA NIM for LLM | 前回、導入したLLMを推論利用するためのAPIサーバー |
| NVIDIA Riva for ASR and TTS | NIM for LLMのUI環境ではASR(音声認識)とTTS(音声読み上げ)機能もオプションで利用可能。(今回は利用しません) |
■NIM for LLMでUI環境を構築してみる
構築は非常に簡単です。Docker Composeを利用するため、起動に関するパラメータ(compose.env)を設定し、あとはDocker Compose を実行するだけで、UI環境が構築できます。なお、前回と同様にNIMを利用するためにはNVIDIA AI Enterpriseライセンスが必要となります。もしH100 GPUを購入している場合は、製品に該当ライセンスが付属していますので、NVIDIA GPU Cloud(https://www.nvidia.com/ja-jp/gpu-cloud/)よりアカウントの作成及びNVIDIA AI Enterpriseライセンスのアクティベーションを行ってください。A100 GPUなどのNVIDIA GPUを所有しているが、ライセンスが無い場合は、無料で90日間試用できますので同じく、NVIDIA GPU Cloudにて登録してください。
利用環境
| サーバー:Dell R750 server (A100 x2枚) |
| OS: Ubuntu 22.04.3 LTS |
|
※GPUドライバー、Docker環境はインストール済みです。なお、LLMとしては前回、NIM for LLMで起動させたmeta/llama3-8b-instructを利用します |
1.環境構築
以下を実行して、NIM用プログラム(GenerativeAIExamples)をダウンロードします。
sudo apt -y install git-lfs
git clone https://github.com/NVIDIA/GenerativeAIExamples.git
cd GenerativeAIExamples/
git lfs pull
2.Docker runtimeの設定
cat /etc/docker/daemon.json を確認し、以下の設定になっていることを確認する。
est@r750:~/GenerativeAIExamples$ cat /etc/docker/daemon.json
{
“default-runtime”: “nvidia”,
“runtimes”: {
“nvidia”: {
“args”: [],
“path”: “nvidia-container-runtime”
}
}
設定が異なる場合は、「sudo nvidia-ctk runtime configure –runtime=docker –set-as-default」を実行してください。
3.DockerコンテナでGPUが認識できているか確認
sudo docker run –rm –runtime=nvidia –gpus all ubuntu nvidia-smi -L
出力結果で、搭載されているGPUのUUIDが表示されることを確認します。
GPU 0: NVIDIA A100 80GB PCIe (UUID: GPU-a7de9f05-c55c-a5ef-2d97-e3fc5136d8c8)
GPU 1: NVIDIA A100 80GB PCIe (UUID: GPU-f80a4bfe-4ee8-6f5f-c0e1-b2fc126e88d0)
4.モデルダウンロードと保存のためのmodel-cacheディレクトリの作成
cd GenerativeAIExamples
mkdir -p model-cache
5.composeファイルの編集
vi deploy/compose/compose.env
以下の行を追加します。
export MODEL_DIRECTORY=”/home/test/GenerativeAIExamples/model-cache”
export APP_LLM_SERVERURL=”meta-llama3-8b-instruct:8000″
export NVIDIA_API_KEY=**** <-前回、NVIDIA GPU Cloudのサイトで発行したAPIキーを指定してください。
6.composeファイルを使ってChain serverとRag playgroundコンテナをビルドする
※各コンテナのビルドファイルもすでに用意されています。
docker compose –env-file deploy/compose/compose.env -f deploy/compose/rag-app-text-chatbot.yaml build chain-server rag-playground
ビルドには時間がかかるため、完了まで待ってください。
7.Chain ServerとRAG Playgroundを起動
docker compose \
–env-file deploy/compose/compose.env \
-f deploy/compose/rag-app-text-chatbot.yaml \
up -d –no-deps chain-server rag-playground
実行後、以下のようにログが出力され、nvidia-ragネットワークが作成され、chain-serverとRag-playgroundコンテナが起動します。
Network nvidia-rag Created
Container chain-server Started
Container rag-playground Started
なお、docker psコマンドでもchain-serverとrag-playgroundのコンテナが起動していることを確認できます。前回起動したmeta-llama3-8b-instructコンテナも起動しているはずです。
また、docker psでコンテナが起動していない場合は、何等かの理由で起動していません。「Docker logs コンテナ名(chain-server、rag-playground、meta-llama3-8b-instruct)」を実行すると各コンテナのコンソールログが出力されるので、ログから原因特定が可能です。
8. Vector databaseの起動
Vector DatabaseにはMilvusを利用しています。以下のDocker Composeコマンドで起動してコンテナを起動させてください。こちらも時間がかかります。
docker compose \
–env-file deploy/compose/compose.env \
-f deploy/compose/docker-compose-vectordb.yaml \
–profile llm-embedding \
up -d milvus
実行後、以下のようにログが出力され、milvus-minio、milvus-etcd、milvus-standaloneの3つコンテナが起動します。
Container milvus-minio Started
Container milvus-etcd Started
Container milvus-standalone Started
9.起動したDockerコンテナの確認
docker ps –format “table {{.ID}}\t{{.Names}}\t{{.Status}}”
CONTAINER ID NAMES STATUS
98e046eca81c milvus-standalone Up 58 seconds
df1abb99b101 milvus-etcd Up 59 seconds (healthy)
b686cf7dd72d milvus-minio Up 59 seconds (healthy)
dd1a1659a1df rag-playground Up 6 minutes
a6547f8f3c08 chain-server Up 6 minutes
148d9bc37d18 meta-llama3-8b-instruct Up 18 hours
上記のコンテナが起動していれば、UI環境の構築が完了です。
※起動したDocker Composeで起動したコンテナは以下のコマンドで停止も可能です。
docker compose -f deploy/compose/docker-compose-vectordb.yaml –profile llm-embedding down
docker compose –env-file deploy/compose/compose.env -f deploy/compose/rag-app-text-chatbot.yaml down
■UI環境を利用しましょう
構築したサーバーからブラウザを利用可能であれば、ブラウザを開き「http://localhost:8090」へアクセスしてください。ポート番号8090はRAG Playgroundのポート番号になります。他のPCからアクセスする場合は、構築したサーバーのIPアドレスをPCのブラウザから指定してください。
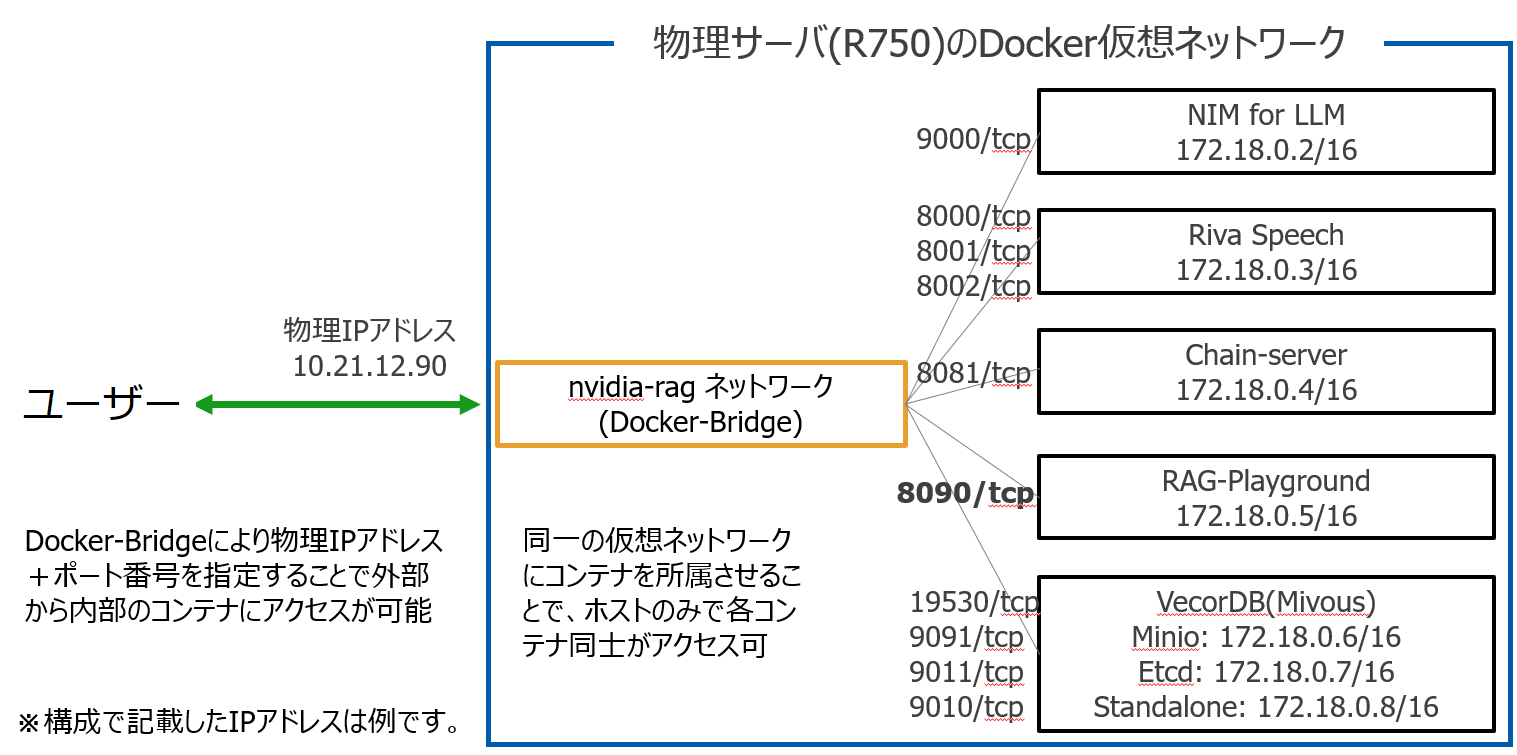
なお、今回は1台のサーバーを使って構築しましたが、Docker Composeで作成したnvidia-rag仮想Dockerネットワーク構成イメージは以下のようになります。
注:前回構築した、meta-llama3-8b-instructコンテナはnvidia-ragネットワークに所属していないため、一旦コンテナを停止し、以下のように–net nvidia-ragを追加してコンテナを起動してください。
docker run -it –rm –name=$CONTAINER_NAME –runtime=nvidia –gpus ‘”device=0″‘ –shm-size=16GB -e NGC_API_KEY -v $NIM_CACHE_PATH:/opt/nim/.cache –net nvidia-rag nvcr.io/nim/meta/llama3-8b-instruct:1.0.0
ブラウザから、RAG Playgroundにアクセスすると以下のConverse画面が開きます。
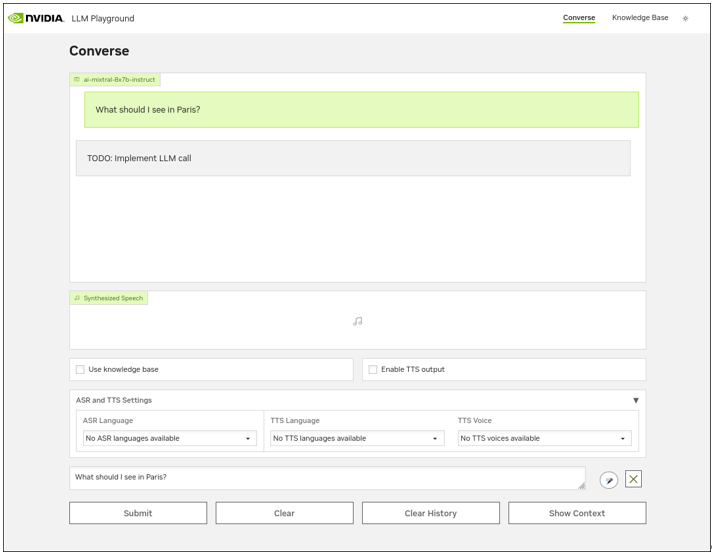
使い方は非常にシンプルなので、是非利用してください。なお、RAGを利用したい場合は画面右上の「Knowledge Base」をクリックすると、RAG用の情報ファイルを登録する画面に遷移するので、RAGで検索拡張したいPDF等を登録してください。登録後は、最初の画面にある「Use Knowledge base」にチェックを入れ利用すると、登録したRAG情報も合わせてLLMにインプットされます。RAG検索された情報はConverse画面の右下にある「Show Context」を押すと表示されます。
■その他、補足
今回の構成の中で、エンベッディングサーバーのコンテナを起動していないことに気づいた方もいるかと思います。理由はエンベッディングサーバーのみローカルで構築せずに、NVIDIAクラウドに設置されている(nvidia-ai-endpoints) エンベッディングサーバーへアクセスし、利用しているからです。これによりローカルGPUの負荷を下げることが可能です。もちろん、NVIDIA NGCからエンベッディングサーバーのコンテナをダウンロードするこで、ローカルに構築することも可能です。
■最後に
如何でしたでしょうか。NIM for LLMを利用することで、簡単に生成AIチャットボット推論環境が構築できることがわかりました。しかもRAG機能も利用できるので、社内で生成AIのオンプレ利用を試験的に行うことも可能だと思います。NIM for LLMでサポートするオープンソースLLMも増えており、今後は独自データを学習させたモデルをNIM for LLMで利用できる計画もあるようですので、LLMは「大手テック企業のものを利用する」から「自社オリジナルLLMを利用する」に変化していくかもしれません。
最後に、ブログをお読みになり、LLM構築及びAIアクセラレータ製品等にご興味がある方は当社までお問合せ頂ければ幸いです。

この記事の投稿者Nakada
Cerebras製品を担当しているエンジニアです。
この記事をシェア

