超高速ディープラーニングシステム「CS-3」

Cerebras | CS-3
Cerebras社のCS-3は、CS-1、CS-2と続くCerebras第3世代の巨大半導体チップを実装したディープラーニング専用システムです。GPUベースの従来システムと比べて省スペース・低消費電力で超高速な学習処理を行うことが可能です。

ピンチアウトで拡大
「CS-3」には、ディープラーニング専用に設計された21.5cm角の大型半導体「ウェハースケールエンジン(WSE-3)」を搭載しています。「WSE-3」は積和演算を実行する90万個のコアと、効率的なデータアクセスのためにコア毎に高速なローカルメモリを実装し、コア間で非常に高速な通信が可能になるように設計されています。
| CS-1(WSE-1) | CS-2(WSE-2) | CS-3(WSE-3) | |
| 製造プロセス | TSMC 16nm | TSMC 7nm | TSMC 5nm |
| シリコン面積 | 46,225 ㎟ | 46,225 ㎟ | 46,225 ㎟ |
| トランジスタ数 | 1.2 Trillion | 2.6 Trillion | 4 Trillion |
| 疎線形代数演算コア | 400,000 | 850,000 | 900,000 |
| オンチップSRAM | 18 GB | 40 GB | 44 GB |
| メモリ帯域 | 9 PB/s | 20 PB/s | 21 PB/s |
| コア間インターコネクト | 100 Pb/s | 220 Pb/s | 214 Pb/s |
|
|
WSE-3 |
Nvidia H100 |
Cerebrasの優位性 |
|
チップサイズ |
46,225 mm² |
826 mm² |
57 X |
|
コア数 |
900,000 |
16,896 FP32 + 528 Tensor |
52X |
|
オンチップ・メモリ |
44 Gigabytes |
0.05 Gigabytes |
880 X |
|
メモリ帯域幅 |
21 Petabytes/sec |
0.003 Petabytes/sec |
7,000 X |
|
ファブリック帯域幅 |
214 Petabits/sec |
0.0576 Petabits/sec |
3,715 X |
WSEの90万個の疎線形代数演算コアは、多くのニューラルネットワーク向けに最適化されています。
各コアはそれぞれ独立して柔軟にプログラム可能であるため、トレンドに合わせてどんなアルゴリズムでも実行することができます。
WSE上の全てのコアは、シリコン上のSwarmと呼ばれる214Pb/sの2次元メッシュ構造の通信ファブリックで相互に接続されています。
シリコン上での通信は、GPU同士間の通信と比べて非常に小さなレイテンシと消費電力で高速通信することが可能です。
WSEはオンチップSRAMを大量実装しており、モノリシックなシリコンチップ上でPB/sクラスのトータルメモリバンド幅でアクセス可能です。
シリコンチップ上の各コアにローカルSRAMを分散配置することで、より低レイテンシで低消費電力を実現しながら高速で柔軟な演算処理が可能になります。
すべてのモデルの重みを外部に保存し、オフチップメモリに関連する従来のペナルティを受けることなく、クラスタの各ノードにストリームすることを可能にする実行モード。ウェイトストリーミングでは、単純なスケーリングモデルで現在の最先端よりも2桁大きなモデルの学習が可能です。
ウェイトストリーミングで利用される外部メモリシステム。MemoryX技術を使用し、すべてのモデルの重みを「オフチップ」で保存し、必要なときにこれらの重みをCS-3システムにストリームします。重みがCS-3を通過すると、WSEは基礎となるデータフロー機構を使って計算を実行し、勾配をMemoryXに戻して重みが更新されるようにストリームバックします。
MemoryXとCS-3クラスタをつなぐ革新的なブロードキャスト/リデュースファブリック。ハードウェアベースのレプリケーションを使用して、すべてのCS-3に重みをブロードキャストし、CS-3からMemoryXに戻される際に勾配を低減します。SwarmXは単なるインターコネクトではなく、データパラレルスケールアウトに特化した学習プロセスのアクティブコンポーネントです。
アプライアンスモードでは、ウェハースケールクラスタをAIモデルの学習サービスとして管理することが可能です。ジョブを投入するだけで、あとはクラスタが処理してくれます。分散コンピューティング、Slurm、Dockerコンテナ、レイテンシなど、インフラについて考える必要はありません。また、クラスタは自動的にリソースを分割して、複数の同時利用者に対応します。

Condor Galaxy は、CS-3システムを複数台で構成したシステムで、アメリカのカリフォルニア州・テキサス州に設置されています。このCondor Galaxyを利用することはAIモデルを構築する最も簡単かつ最速の方法です。
ExaFLOP級のAIコンピューティングを備え、最も要求の厳しいモデルを数日ではなく数時間でトレーニングします。テラバイト規模のMemoryXシステムを搭載しており1,000 億を超えるパラメータモデルをネイティブに対応し、大規模なトレーニングをシンプルかつ効率的にします。

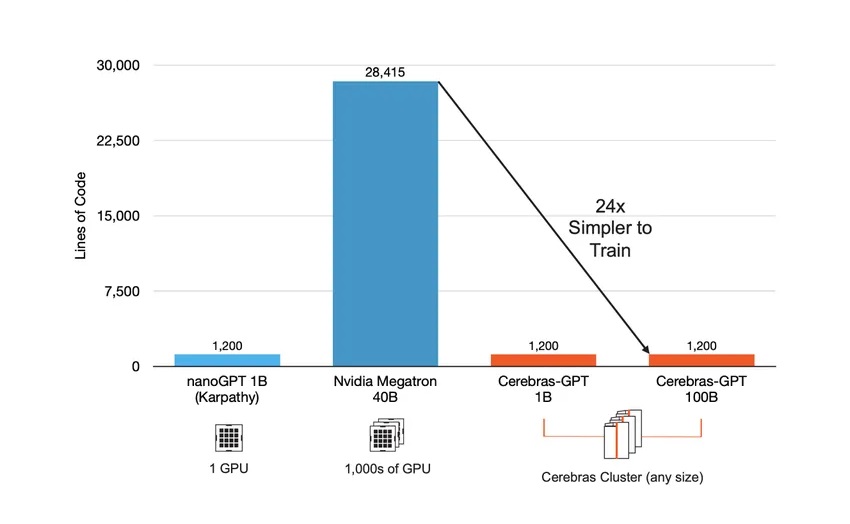
Condor Galaxyはウェハ―スケールクラスタで構成されているため、1台のシステムとして利用することが可能です。そのため、従来のGPUクラスタシステムで必要だったクラスタに関するプログラミング無しでAIモデルのスケールアップが簡単に実行できます。
Condor Galaxyは、既知のGPUベースのクラスタとは異なり、GPTクラスの大規模言語モデル間でほぼ完璧なスケーリングを提供します。ほぼ完璧なスケーリングとは、追加のCS-3が使用されると、トレーニング時間がほぼ完璧に短縮されることを意味します。
生成AIモデルのセットアップは数ヶ月ではなく数分で完了し、一人で行うことが出来ます。