企業における命題であるBC/DR(Business Continuity / Disaster Recovery : 災害復旧と事業継続)やITSCM(ITService Continuity management:ITサービス継続性管理)など高い可用性が要求されるミッションクリティカルなアプリケーションは、一般的にシステムの冗長化やレプリケーション等の方法で保護されていますがRPO(Recovery Point Objective:目標復旧時点) とRTO(Recovery Time Objective:目標復旧時間)の設定と実現は常にシステム設計者の悩みです。
ピュア・ストレージのActiveCluster技術は“RPO /RTO ゼロ” を簡単に実現することが可能な技術です。
本資料は下記よりダウンロードいただけますPDFダウンロードはこちら
これまで、東京エレクトロンデバイスが販売してきた数多くのピュア・ストレージ製品において、機器が完全に停止した実績はありません。しかしながら、お客様によっては過去のストレージ運用の中で、冗長構成にもかかわらず災害やシステム障害によってストレージが停止してしまったという経験から、不安をお持ちの方も少なくありませんでした。今回ご紹介するActiveClusterはそのような不安やお悩みをお持ちのお客様に評価・導入いただいているソリューションです。システムの信頼性・堅牢性を高めつつ、より安全・簡単に導入可能なそのActiveCluster 技術について紹介します。
真のActive/Active Solution
RPO/RTOゼロの実現
Mediatorの設計、構築不要
これまでの同期レプリケーションでは、データを複製するが実際使用しているボリュームは一つで、同様の物が対向ストレージにスタンバイとして配置するのが一般的な手法でした。
ピュア・ストレージ社のActiveClusterは互いのアレイにて同期レプリケーションを用いてデータを共有するまでは過去のアーキテクチャと同等ですが、互いのアレイのボリュームは実際にActive/Activeであり、Read/Writeが可能な状態となっています。よってホストから見ると、実際2基あるストレージはあたかも1基に見え、コントローラヘッドが増えたように振舞います。そのため非同期レプリケーションのようにレプリカより復元などもなく、完全同期レプリケーションにより“ゼロ RPO/RTO”を実現します。
また、ActiveClusterではMediatorという仲裁者によって監視・管理が常に行われており、片側のアレイなどに障害が発生した際は瞬時に誰がオーナーになるべきかを判断し、ストレージへのRead/Writeを継続することができます。Mediatorはピュア・ストレージのCloudサポート基盤であるCloudAssistに配置されており、お客様はMediatorの管理、構築、メンテナンスをすることなく使用できます。
構成の主なコンポーネントは下図のようになっています。

ピンチアウトで拡大
ピンチアウトで拡大
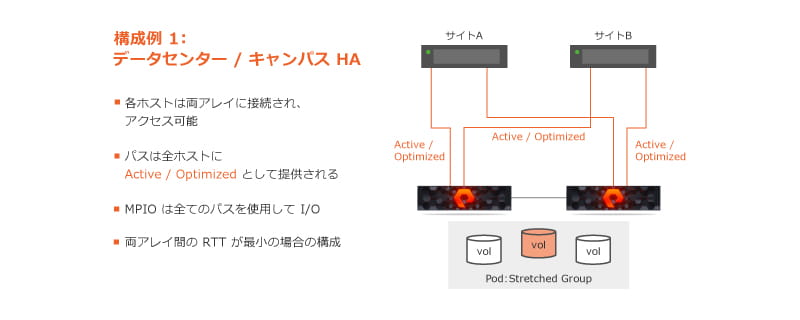
同一データセンター(以下、DC)やキャンパスにおいて、機器故障を加味した構成でRTT(Round Trip Time)が極小の場合はホストからは両アレイともOptimizeされたパスと認識され、マルチパスI/Oにて両アレイに均等にRead/Writeが実行されます。 Writeは両アレイに書き込まれてコミットを返すため、アレイは常に同等のデータを保持します。

ピンチアウトで拡大
Metroエリアの構成では各ホストにPreferred Arrayをピュア・ストレージ上で設定します。Writeは両アレイに書き込みを行う必要があります。ReadにおいてはOptimizedのパスが設定されるため直近のアレイから読むためReadの性能ペナルティはありません。
1) 冗長化されたレプリケーション通信経路がダウンした場合

ピンチアウトで拡大
同一DCでは両系のスイッチがダウンしている事と同等であり、珍しい状況ですが、メトロHAではサイト間の通信ができないケースが想定されるため、このような事態になった場合、アレイはCloudAssist上のMediatorに通信を行い、先に通信が実施できたほうのアレイがオンラインとして動作し、もう片方はオフラインとなります。 そのため、DCキャンパス構成では単にクラスタ内のコントローラヘッドが減った挙動となり、メトロ構成ではNon-Optimizedパスが使用された形で通信が継続されます。
2) 冗長化されたMediator通信経路がダウンした場合
Mediatorアクセスは冗長性を持たせるために各コントローラの2ポートのマネージメントネットワークポートを使用し通信を実施します。この冗長化されたマネージメント通信ができない場合でも、レプリケーションの通信経路を使用し、互いのアレイのステータスを確認し、両アレイにてI/Oが継続されます。
3) 各障害時の挙動まとめ

ピンチアウトで拡大
基本的に一つの障害では継続か縮退動作にてストレージ機能の継続提供が可能です。
クラスタとして停止するのは以下の2通りの場合があります。
・片方のアレイが完全停止(冗長のコントローラダウン) & 冗長されたMediator通信のダウン
・冗長化されたレプリケーション通信ダウン &冗長されたMediator通信のダウン
つまり、冗長化された各々の2つの部位が同時に障害とならない限りクラスタは動作します。
4) 片アレイでの動作したあとのデータの同期方法

ピンチアウトで拡大
片方のアレイが復旧する際は、最初にアレイ間の差分を埋めるべく、非同期レプリケーションにて同期を開始します。その後、データが同期する直前で両アレイに書き込みを実施し同期レプリケーションの機能として動作を自動的に切り替え、Active/Activeとして動作を再開します。
ActiveClusterはお客様でのストレージ運用を極小化し、システム全体の保護レベルを最大化する機能です。
近年、データは価値という時代となっており、常時オンラインでサービス停止が一切許されないというお客様に評価され、当該機能を利用したピュア・ストレージの導入事例が増加しています。
ミッションクリティカルなシステムを運用されているお客様は、一つの選択肢として当該機能を検討してみてはいかがでしょうか。
.general_lay.__white { background-color: transparent; }