
バズワードからの脱却、ビッグデータ活用はデータを溜め込まない第2フェーズへ
-

-
谷川耕一
2015年10月23日
日本で「ビッグデータ」という言葉が使われ始めたのは2011年頃からだろう。 当初は“バズワード”とも言われ、実体感が伴わないなか、ベンダーが先行する形でマーケティング用語などとして利用した。とはいえ、企業の競争力を高めるキーワードとしては評価され、ビッグデータ関連記事へのアクセスもかなり多く、イベントやセミナータイトルにもこの言葉は多用された。それから4年あまりが経過、「ビッグデータを活用しています」と胸を張って言える企業はどれくらいいるだろうか。莫大な量のデータが“宝の山”であろうことは理解できても、それを活用するのはベンダーが言うほど簡単でないこともわかってきた。
データ量が増えれば簡単には扱えない
ビッグデータを活用する際に何が大変かと言えば、それはやはりデータ量の多さだろう。
数100テラバイトのデータを軽快に扱えるデータベースを運用しようとすれば、かなりハイエンドなサーバーも必要となる。高速な検索を実現するにはチューニングなどの手間もいる。また非構造化データを扱いたいとなれば、HadoopやNoSQLなどこれまで使った経験のないシステムも扱わなければならない。それには運用や開発に関する新たなスキルも必要だ。とくにHadoopなどを数100ノード規模で運用するとなれば、それ相応の運用知識がいる。
もう1つ、増え続けるデータをどこまで蓄積し続ければいいかといった判断も難しい。ストレージが安くなったとはいえ、データ量の増大に合わせ、次々とディスク装置を増やすわけにはいかない。ストレージ購入代金はもちろん、スペースや稼働時の電気代なども増大する。さらにデータが増えれば、ストレージだけでなく、
データベースサーバーも性能確保のために増強しなければならない。
ビッグデータは宝の山かもしれない。しかし、それを掘り起こす前段階ではどんな宝なのかがわからないことも多い。明確な効果がわからないものに投資を続ける判断は、経営者にはなかなかできない。
そのため、ビッグデータ活用なのに「小さく始める」なんてことも起こり得るのだ。
もう1つの課題が、ビッグデータから価値ある知見を導き出すにはデータサイエンティストが必要ということ。
多様で莫大なデータから知見を導き出すには、単純なBIではなかなかうまくいかない。データサイエンティストと呼ばれるような統計処理などの高度なスキルを持った人材が必要だと言われている。とはいえ、そんな人材はなかなかいない。そういった人材を育成するのも簡単ではない。
大量データを集めないビッグデータ
数100テラバイト規模のデータを溜め、それを高度に分析するには、高性能なデータベースと大規模な
ストレージが必要だ。規模が大きくなれば処理には時間がかかることになる。もちろん時間をかけて分析しなければ得られない知見もある。しかし時間をかけて高度な分析を施しても、得られた結果は現場専門家からすれば「そんなことはわかっていたよ」と言われてしまう場合だってある。
ビッグデータをうまく活用できている事例を見ると、ビジネス課題がはっきりしているところに適用したものが多い。プロセスで無駄が多いところや、人が介していたのではタイムリーな判断ができなかったところを、
データの力で効率良く判断できるようにする。結果的にデータを解釈して自動化できれば、かなりの成果が上がることになる。たとえば、いったんはデータを溜め込んでそれを分析して状況を把握する。この分析に利用されるのはデータサイエンティストが行うような高度な統計処理であったり、最近流行の機械学習だったりするだろう。
当初のビッグデータ活用と変わってきたのが、この高度な分析をするのに、
必ずしも自前のデータサイエンティストが必要というわけではなくなりつつあることだ。
データ分析の難しいところはなるべくツールなりに任せるのが、賢いデータ活用である。クラウドサービスでも機械学習処理エンジンなどが簡単に利用できる。これらを積極的に利用すれば、データ分析の専門家が社内にいなくても、ある程度の分析は可能となってきた。
したがって、高度な分析が行えるツールやクラウドサービスなどを用い、意思決定判断を行うための分析モデルを作ることも可能だ。
この判断のためのモデルを使って自動処理エンジンさえできあがれば、
あとは流れてくるビッグデータをリアルタイムに処理し、素早くアクションを起こすことができる。
このようなストリームデータの処理が、ここ最近は溜め込むビッグデータ活用よりも注目を集めている。
ストリームデータをリアルタイム処理するには、技術的にはインメモリデータベースやフラッシュストレージなど高速処理の仕組みも必要だ。
そういったものが、最近では比較的安価に利用できることも、ストリームデータ処理を後押ししている。
実際、金融の不正取引検知や通信業者の離脱顧客の防止などで、このストリームデータ処理による
ビッグデータ活用が始まっている。いま流行のマーケティングオートメーションの世界においても、ECサイトでのリアルタイムなリコメンデーションや顧客行動に応じたタイムリーなメッセージのプッシュ配信なども、
ストリームデータ処理と同様の考え方だと言える。
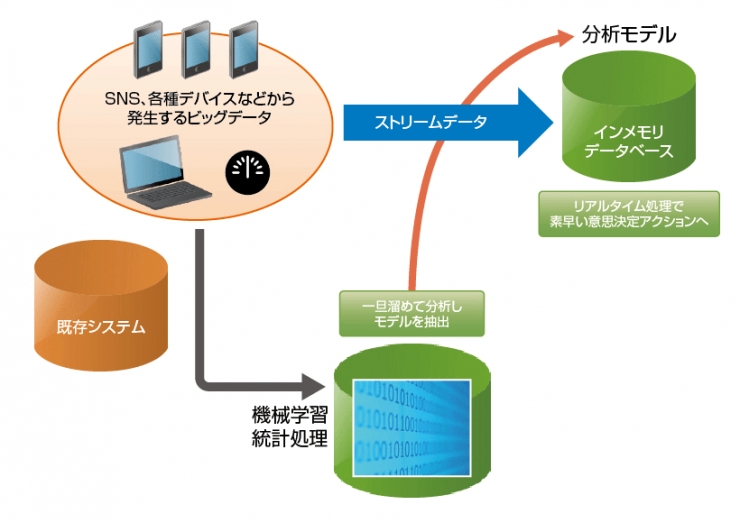
図1 パブリッククラウドは「過酷なIaaS価格競争」が始まっている
IoTが溜め込まないビッグデータをさらに後押しする
データを溜め込まないビッグデータ活用をさらに後押ししているのが、
いまIT業界で話題の「IoT(Internet of Things)」だ。
IoTはあらゆるものがネットワークで接続され、デバイスから生まれるログなどのデータをクラウドに集めて活用しようというものだ。PCや既存のシステムなどから生まれるビッグデータよりも、IoTで生まれるビッグデータはデバイスの数が桁違いなので、はるかに多くなる。つまり、IoTとビッグデータ活用は密接に関係するものなのだ。
そんなIoTのビッグデータをいちいち1カ所に集めていたのでは、ストレージがいくらあっても足りない。
仮にクラウドになんとか集められたとしても、それを分析し、なんらかの知見を得て結果を返すのに数日間かかるなんてことになれば、分析結果を受け取ってデバイスを自動制御といったことはできないだろう。
また大量に発生するデータをインターネットなりのネットワーク経由で安全且つタイムリーに集めるのも、かなりの手間とコストが必要だ。
そこでシスコなどから提唱されているのが、フォグコンピューティングやエッジコンピューティングと呼ばれる新しい考え方だ。これはなるべくデバイスに近いところで予めデータを処理し、必要なデータ、有用だと思われるデータだけをクラウドなどに集めるようにするもの。IoTで生まれる全てのデータが利用価値の高いものとは限らない。生まれるデータを何も考えずにひたすら溜め込むのではなく、なるべくデバイスに近いところで前処理し、ネットワークを行き交うデータ量を小さくするのだ。
この場合の「フォグ」とは、クラウドという“雲”とデータが発生するデバイスの間にある“霧”のこと。クラウドで集中処理するのではなく、フォグで分散処理を行う。これによりデータの集中化による処理の遅延を防ぎ、
IoTのビッグデータをネットワーク上でスムーズに流通させる。
デバイスのより近くで処理すれば、それは“エッジコンピューティング”と呼ぶほうがしっくりくるだろう。

図2 フォグやエッジで分散処理してクラウドへ渡すのは必要なデータだけ
データを溜め込むならデータレイクを作れ
もちろん溜め込んだ大規模なデータに対し、高度な統計処理などの分析を試行錯誤しながら時間をかけて行うことで“貴重な宝”が手に入るかもしれない。それを得るために、HadoopやNoSQLデータベースとハイエンドな
リレーショナルデータベースを連携させる“溜めることで価値を生み出すビッグデータ活用”の仕組みもある。
この溜めるビッグデータ活用で最近キーワードとなっているのが「データレイク」という考え方だ。
データレイクは、どのようにデータを分析するかをあらかじめ決めるのではなく、生まれてくるデータを(理想的には全て)データレイクにどんどん蓄積する。
データレイクは多くの場合、Hadoopなどの技術を用い非構造化データを容易に蓄積でき、拡張性にも優れた環境となるようにする。もちろん、溜めるデータには構造化データもあるので、
その場合は拡張性の高いリレーショナルデータベースを組み合わせることになる。
ポイントは、単に大量データを安価に溜め込める環境ではなく、集めているデータに自由にアクセスできる方法を提供することだ。この「自由に」という部分には、速度も重要な要素であり、誰もが簡単にアクセスできるような使い慣れたSQLインターフェイスを持つことにもなる。
また、最初から巨大なデータレイクを作るのではなく、結果的に大きなデータレイクになっても自由にアクセスできるようなアーキテクチャを採用する。データレイクは、そういう意味では小さく始めて大きく育てるという発想も必要だろう。
とはいえ、多くの場合、大量データを1カ所に溜め込んでしまうと動きは鈍くなりがちだ。どんなデータをどれくらい溜めるのか、どんなデータであれば溜めずに素早く処理すべきなのか。その見極めが、ビッグデータ活用の成否を左右する。
※このコラムは不定期連載です。
※会社名および商標名は、それぞれの会社の商標あるいは登録商標です。
-
谷川耕一/Koichi Tanikawa
実践Webメディア「EnterpriseZine」DB Online チーフキュレーター
http://enterprisezine.jp/dbonline
ブレインハーツ取締役。AI、エキスパートシステムが流行っていたころに開発エンジニアに。その後、雑誌の編集者を経て外資系ソフトウェアベンダーの製品マーケティング、広告、広報などを経験。現在はオープンシステム開発を主なターゲットにしたソフトハウスの経営とライターの二足の草鞋を履いている。





