NVIDIA GPUでお手軽構築AIパイプライン

昨今、企業におけるAI活用は当たり前になっており、世の中にはAIを用いた様々なサービスが溢れています。しかし、AIを使うだけでなく、オリジナルのAIを作成し、競合企業に一歩差をつけたいと考える方も増えてきているのではないでしょうか。
今回のブログでは、そんなオリジナルAIを作ってみたいという方向けに、NVIDIAソフトウェアスタックを用いたお手軽簡単AIパイプラインの構築について紹介したいと思います。
AIモデル作成のハードル
AIモデルを一から作成しようと考えた場合、最初に思い浮かぶハードルはやはり計算リソースではないでしょうか。ご存知の通り、ディープラーニングの学習にはGPUなどの強力な計算リソースが必要であり、その調達(クラウド or オンプレ、GPUサイズ等)に頭を悩ませる方も多いと思います。しかし、オリジナルAIを作成し、活用するまでには他にも検討しなければいけない様々なハードルがあります。

実際にオリジナルAIを活用するため、図のように簡単なAIパイプラインを考え、各段階で検討する必要のある課題について見てみましょう。
データ準備
まず初めに、オリジナルAIモデルの作成には、モデルの学習、評価のために大量のデータが必要になります。さらに、これらの大量データをAIモデルの精度を損なわないようにクリーニングし、実際のモデルが読み込めるよう前処理する必要もあります。このクリーニングや前処理は、使用するデータの種類ごとに適切な方法を用いる必要がありますし、データ量が増えるほどデータを保管しておくためのストレージや処理を実行するための計算リソースについても検討が必要になるでしょう。
学習
オリジナルAIモデルの学習では、前述のように計算リソースについて考える必要があります。加えて、準備できる計算リソースの範囲で現実的に実行可能なハイパーパラメータ(バッチサイズなど)や並列計算(データパラレルやモデルパラレル)についても検討が必要になります。
評価
評価の段階では、作成したAIモデルが実際に使用可能かどうかを判断することになります。ここで期待した精度が得られなければ、データ準備、学習の段階から様々な設定を見直す必要がでてきます。評価自体も、単に精度を達成すれば良いというわけではなく、この後の推論の段階でデプロイ可能なAIモデルとなるようモデルの軽量化について考え、軽量化したモデルの再学習やキャリブレーションなども考えなければいけません。
推論
AIパイプラインにおける推論とは、作成したAIを実際に活用する段階です。作成されたモデルをどこに配置し、エッジからのデータをどのように取り込み、モデルの出力をどのようにアプリケーションへと反映させるのか、考えなければいけない課題は数多くあります。
以上のように、オリジナルAIの作成から活用までには、簡単なAIパイプラインで考えても数多くのハードルがあることに気付くのではないでしょうか。これら多くのハードルを解決し、オリジナルAIを活用していくには多くの時間と労力がかかってしまいます。しかし、次に紹介するNVIDIAソフトウェアスタックを適切に活用すれば、実は、これまでに挙げた多くのハードルを解決することができるのです。
NVIDIAソフトウェアスタックを使用したお手軽パイプライン
NVIDIAでは、GPUを有効に活用するためのソフトウェアが数多く用意されており、その多くは無償で利用可能です(一部ライセンスが必要ですが、GPUによってはこのライセンスが付帯しているものもあります)。
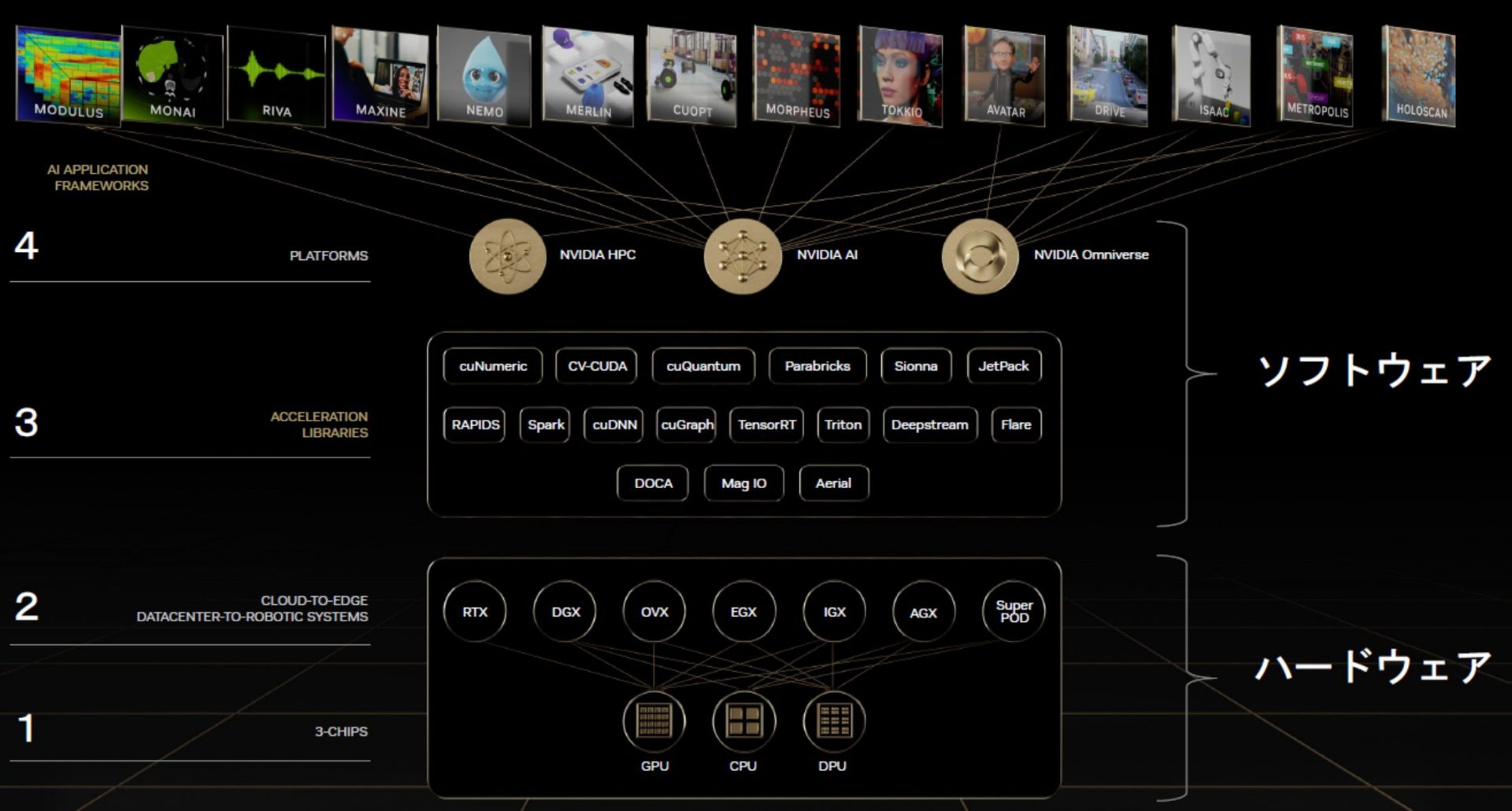
※参照:NVIDIA
とくにAI関連のフレームワークは充実しており、これらを組み合わせることで簡単にAIパイプラインを構築することが可能です。例えば、以下の図のようにTAO TOOLKITとDEEPSTREAMを組み合わせるだけで、先述したハードルの多くを解決することができます。
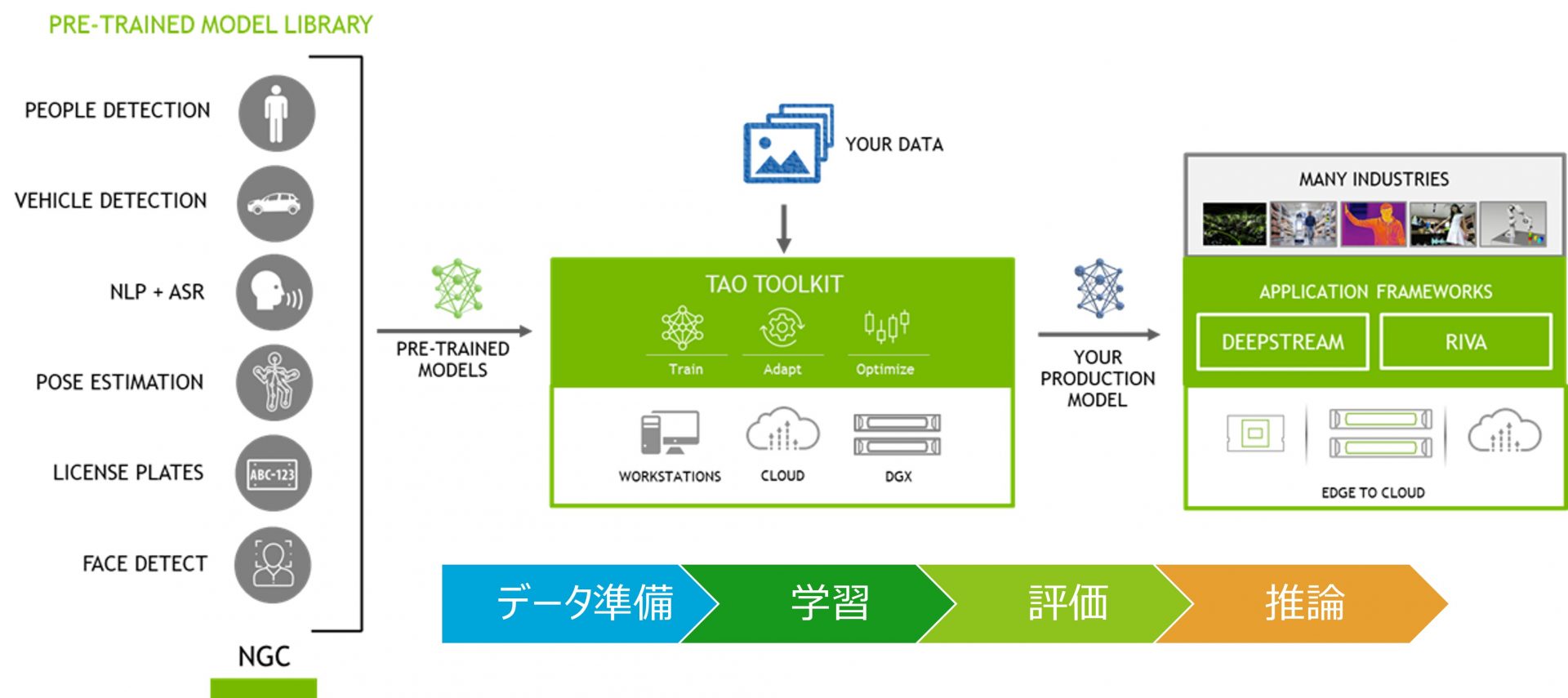
※参照:NVIDIA
TAO TOOLKITでは、AIパイプラインのために簡素化されたCLIが提供されており、これを利用することでデータの前処理からモデルの学習、評価、軽量化までを簡単に実行することができます。TAO TOOLKITの詳細については、過去ブログに記載していますので、そちらをご参照ください。
※過去ブログ:NVIDIA TAO Toolkitを使ってみた
このTAO TOOLKITにより、AIパイプラインにおけるデータ準備から評価までのプロセスは簡単に実行され、推論環境に合わせたモデルを出力することができます。さらに、出力されたモデルをDEEPSTREAMによって推論環境へとデプロイすれば、先述の多くのハードルを解決しつつ、すぐにでもオリジナルAIの活用を始めることができるでしょう。※DEEPSTREAMについては次の章にて簡単に紹介します。
また、これらのソフトウェアスタックを活用することは、AIパイプラインの実行を簡略化するだけでなく、計算リソースの問題も解決してくれます。NVIDIAソフトウェアスタックはほとんどの処理においてGPUリソースを使用するため、AIパイプラインの様々な処理の実行をGPUにより加速します。加えて、多くのGPUリソースを必要とする学習以外の工程においてもGPUを活用できるため、AIパイプラインを通してGPUリソースがより効率的に使用可能になるでしょう。
推論環境を簡単にデプロイできるDEEPSTREAMとは
NVIDIA DEEPSTREAMは、AIベースのマルチセンサー、ビデオ、画像処理のためのストリーミング分析ツールキットです。ニューラルネットワーク、トラッキング、ビデオエンコード/デコード、ビデオレンダリングなどの複雑なタスクを組み込んだストリーム処理パイプラインが作成できます。
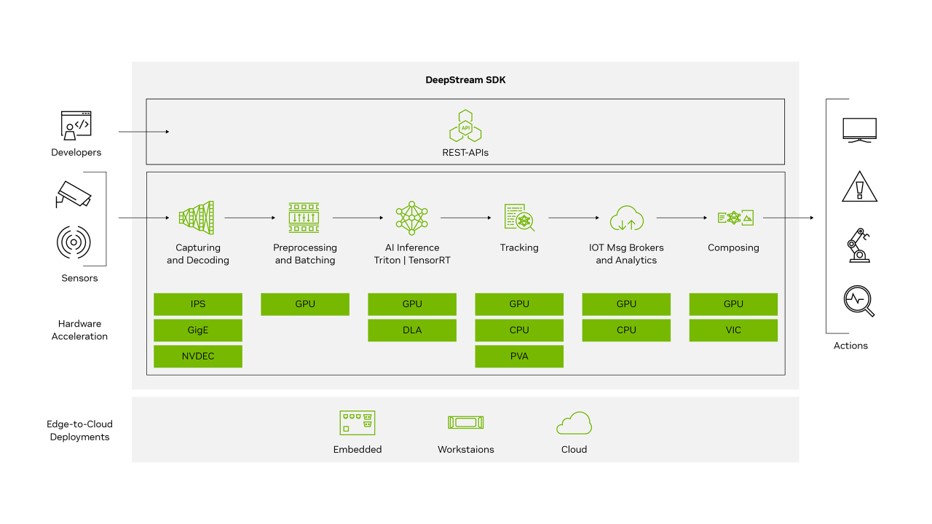
※参照:NVIDIA
このDEEPSTREAMにより、推論環境の開発者は簡単なAPIを使って、TAO TOOLKITで作成したAIモデルを含む推論アプリケーションを作成することができます。実際にDEEPSTREAMを使ったAIモデルを含むサンプルアプリケーションを見てみましょう。

この画像は、物体検出モデルを含むサンプルアプリケーションを実行した際の画像です。道路を映したサンプル動画を入力していますが、物体検出モデルにより走る車や歩く人が適切に検出されていることがわかると思います。このようにDEEPSTREAではAIモデルを含むアプリケーションを容易に作成することが可能です。
最後に
今回のブログでは、NVIDIAソフトウェアを使った簡単AIパイプラインについて紹介させていただきました。本稿を読んで、オリジナルAI作成に挑戦してみようと感じていただけたなら幸いです。
もし「NVIDIAソフトウェアスタックを使ってみたいが環境が無い」、「設定方法や使い方がわからない」などの理由でお困りの場合には、ぜひ当社にご相談ください。当社では、TED AI Lab環境をお客様へお貸出しするTED AI Lab Engineering Service(TAILES)というサービスを提供させていただいております。TAILESでは、単に機器をお貸出しするだけでなく、当社エンジニアが環境設定から使用方法まで手厚くサポートさせていただいておりますので、本稿にて紹介したようなAIパイプラインを即座に体験することができます。
ブログをお読みになり、NVIDIA製品、TED AI Lab、TAILESにご興味がある方はぜひ当社までお問合せ下さい。

この記事の投稿者goto
この記事をシェア