大規模言語モデルの最適化のためのDPO 実践編 (中編)

当社では、Cerebras CS-3を用いてllama-3-8Bを基盤モデルとしてに日本語コーパスによる継続事前学習を施した生成AIモデル、llama3-tedllm-8Bを開発しました。本記事では、DPOを使った自然言語モデルのチューニング手法をご紹介します。
前回の記事(大規模言語モデルの最適化のためのDPO 前編)ではDPOの概要を紹介しましたが、今回はDPO実践編と題してTEDLLMのAligningの実践と評価結果を紹介したいと思います。
DPOの簡単なおさらい
-
LLMの出力を、ユーザー(人間)にとって好ましい安全かつ有益な情報に近づけるようチューニングすることをAligningと呼びます。
-
Aligning手法の一つとして、プロンプトに対するLLMの応答を評価する報酬関数を用意し、この報酬関数によって与えられるスコアを最大化するようLLMをチューニングするRLHF(Reinforcement Learning from Human Feedback)があります。
-
このRLHFが抱える複雑性や演算コストといった課題を解決し、単一の関数最適化によってAligningを実現することができる手法がDPO(Direct Preference Optimization)です。

https://arxiv.org/abs/2305.18290より
DPOチューニング手法の概要
-
演算装置としては、DGX A100を使用します。
-
今回DPOを行う方法としてはtrlライブラリを使用し、LoRA(Low-Rank Adaptation)による低次元層のみの重み更新によるチューニングを行うためにpeftライブラリを使用します。
-
DPOによるAligining用データとしては、aya-ja-evol-instとac-self-instを利用します。LLM-jpが発表しているLLM-jp-3 instruct3で用いられている手法を踏襲した前処理を行いDPOに使用します。
DPO用データセットの準備
使用データセット
DPOでは、以下の形式のレコードからなるデータセットを用いることで、与えられた指示に対してLLMがより好ましい回答を選好するよう調整を行います。
- Prompt: モデルへ入力として与えられる指示文
赤、青、黄という色の名前をそれぞれ英語に変換すると、それぞれ「red」、「blue」、「yellow」となります。これらの英単語に共通するアルファベットはどれでしょうか?
- Chosen: Promptの指示に対する望ましい回答文
赤、青、黄という色の名前をそれぞれ英語に変換すると、「red」、「blue」、「yellow」となります。これらの英単語に共通するアルファベットは「e」です。それぞれの単語に「e」が含まれています。
- Rejected: Promptの指示に対する望ましくない回答文
これらの英単語に共通するアルファベットは「r」です。
※ サンプルは weblab-GENIAC/aya-ja-evol-instruct-calm3-dpo-maskedより抜粋
上記の例だと、ChosenがPromptに対する正しい回答であり、Rejectedは誤った回答であることが分かります。Aligningでは回答の正誤のみでなく、人間のさまざまな選好に基づいたデータが用いられます。
今回は、データセットとしてllm-jp/aya-ja-evol-instとllm-jp/ac-self-instを使用します。llm-jp/aya-ja-evol-instはweblab-GENIAC/aya-ja-evol-instruct-calm3-dpo-maskedのプロンプトに対してChosenをQwen2.5-32B-instructで、Rejectedをllm-jp-3-1.8b-instructで生成したものであり、主に推論精度向上のために用います。また、llm-jp/ac-self-instはモデル出力の安全性を高めることを目的として用います。
データセットの前処理
データセット前処理用のスクリプトとして、LLM-jp instruct3で使用されたコードが公開されているので、これを利用させていただくこととします。ただし、利用する上でいくつか注意点があるため、以下に留意した若干の変更が必要となります。
- 今回はtrlライブラリのDPO Trainerを用います。DPO Trainerでの学習に用いるデータセットのキーは”prompt”, “chosen”, “rejected”の形式である必要があるので、この処理部分を変更します。(元のスクリプトはNeMo DPO-Alighner用のためキー名が異なります)
- このスクリプトには、プロンプトにテンプレートやフォーマットを追加する処理が含まれます。今回はllama3-tedllm-8bをベースモデルとして用いるため、llama3用フォーマットを適用するように変更します。
具体的には、以下の変更を行いました。
8a9,16
> template_llama3_format = “””<|begin_of_text|><|start_header_id|>システム<|end_header_id|>
>
> 以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。<|eot_id|><|start_header_id|>指示<|end_header_id|>
>
> {}<|eot_id|><|start_header_id|>応答<|end_header_id|>
>
> “””
>
14,18c22,24
< “prompt”: “<s>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。\n\n### 指示:\n”
< + sample[“prompt”]
< + “\n\n### 応答:\n”,
< “chosen_response”: sample[“chosen”],
< “rejected_response”: sample[“rejected”],
—
> “prompt”: template_llama3_format.format(sample[‘prompt’]),
> “chosen”: sample[“chosen”],
> “rejected”: sample[“rejected”],
50,54c60,62
< “prompt”: “<s>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。\n\n### 指示:\n”
< + prompt
< + “\n\n### 応答:\n”,
< “chosen_response”: sample[“chosen”],
< “rejected_response”: sample[“rejected”],
—
> “prompt”: template_llama3_format.format(prompt),
> “chosen”: sample[“chosen”],
> “rejected”: sample[“rejected”],
このスクリプトを適用することで、以下のフォーマットのデータセットがjsonl形式のファイルとして作成されます。訓練用データとして92079件のサンプルを、評価用として4845件のサンプルを使用します。
{
“prompt”: “<|begin_of_text|><|start_header_id|>システム<|end_header_id|>\n\n以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。<|eot_id|><|start_header_id|>指示<|end_header_id|>\n\n赤、青、黄という色の名前をそれぞれ英語に変換すると、それぞれ「red」、「blue」、「yellow」となります。これらの英単語に共通するアルファベットはどれでしょうか?<|eot_id|><|start_header_id|>応答<|end_header_id|>\n\n”,
“chosen”: “赤、青、黄という色の名前をそれぞれ英語に変換すると、「red」、「blue」、「yellow」となります。これらの英単語に共通するアルファベットは「e」です。それぞれの単語に「e」が含まれています。“,
“rejected”: “これらの英単語に共通するアルファベットは「r」です。“
}
訓練用パラメータの設定
LoRA
今回は訓練手法としてLoRA(Low-Rank Adoptation)を用います。LoRAはfine-tuningの一種であり、訓練時のフォワードプロパゲーションでは元のモデルが持つ重みと低次元の重みA,とBからなる低次元層の計算結果を足し合わせて出力を算出し、バックプロパゲーションではAとBの重みのみを更新するという手法です。
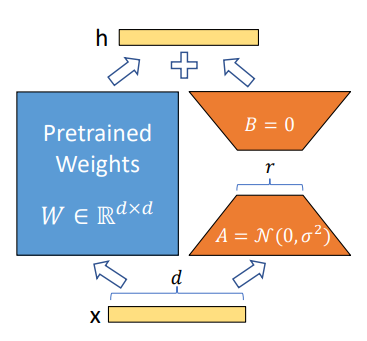
https://arxiv.org/pdf/2106.09685より、LoRAによる低次元の近似パラメータのイメージ
全パラメータを更新するfull parameter fine-tuningと比較すると、主にバックプロパゲーション中に必要な計算量やメモリサイズを大幅に削減することができます。また、保存するcheckpointの容量もAとBの重みのみであるため、ディスク容量を節約することも可能です。
LoRAで追加したcheckpointのファイルサイズは280MB程度。full parameterで訓練した場合、ベースとなるモデルのcheckpoint (llama3-tedllm-8b)の31GBと同程度のサイズとなる。
今回主に使用したLoRAのパラメータは以下の通りです。
- Rank = 8: 付与する低次元層のパラメータ数
- Alpha = 16: 低次元層のパラメータ更新時に用いる勾配の係数
- Target Modules = “.*_proj”: 低次元層の付与対象となる層。今回は全ての全結合層を指定
- DropOut = 0.05: 学習時の汎化性を維持するためのドロップアウト率
DPO
DPOのパラメータは殆どをDPO Trainerのデフォルト値のまま使用していますが、betaのみは0.1と0.5の二通りを使用しています。betaは前回の記事の数式に含まれるβの値であり、元となるリファレンスモデルによる出力とDPOチューニング対象となるモデルによる出力の類似度に影響します。βが大きいほどチューニング対象のモデルは元のモデルによる影響を強く受けます。
その他
その他のパラメータは以下の通りです。
- 学習率 = 5e-7
- WarmUp率 = 10%
- 学習epoch数 = 1
- グローバルバッチサイズ = 12 (3 GPUs × GradientAccumulationSteps=4)
訓練の実行
上記のデータセットと設定を用いてDPOの訓練を実行します。
訓練中の各種指標の推移を確認すると、1 epochの訓練でeval/loss (評価用データセットに対する損失の値)が収束しきっていることが分かります。
今回は、DPOを利用したモデルのチューニング手法をご紹介しました。次回の記事では日本語のベンチマークを使用して、DPOでチューニングしたTEDLLMの評価結果をご紹介します。
大規模言語モデルの最適化のためのDPO (前編)はこちら>>
この記事をシェア

